Learning
Thus far, we've been investing a lot of energy discussing *what we do* once we have some model of an environment, how we use it to perform inference, etc...
What we haven't yet seen in-depth is where that model comes from, or ways of learning key pieces of the model rather than constructing them in a top-down fashion.
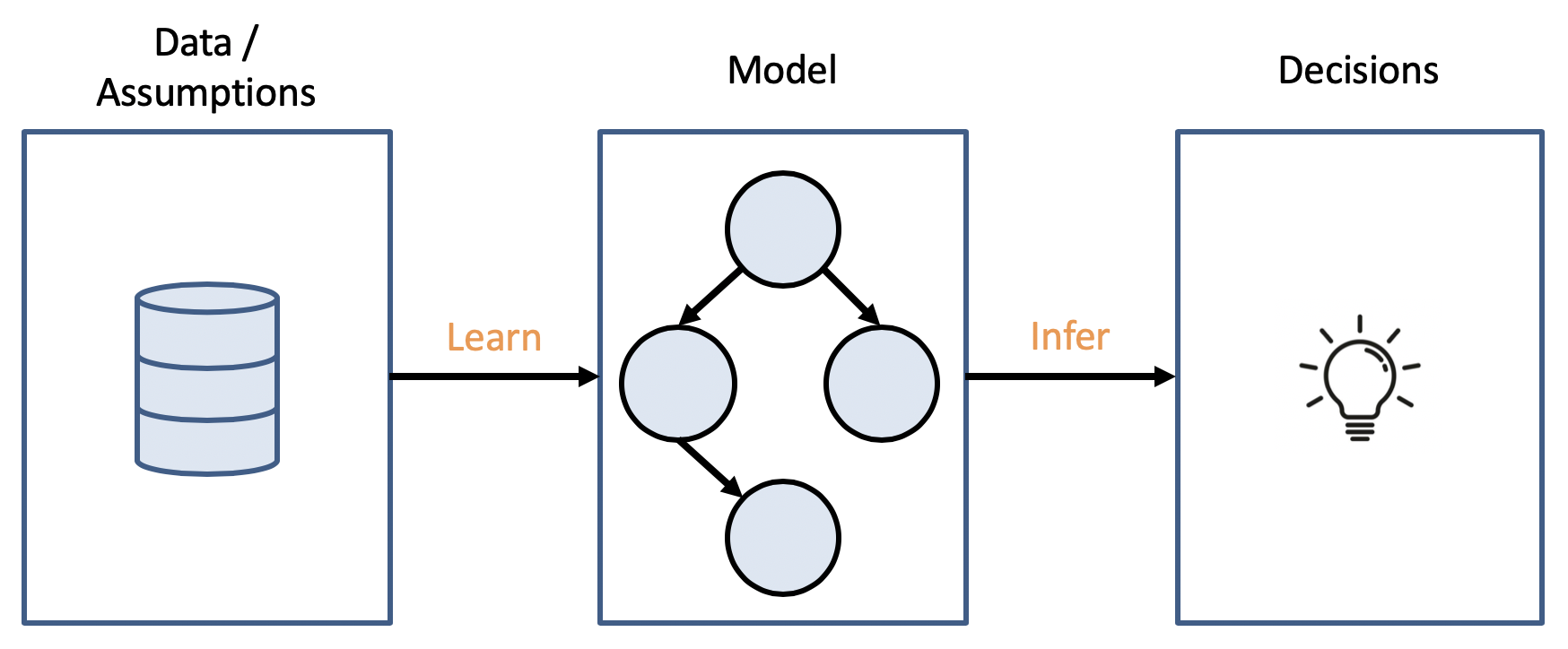
However, that is not to say that we may not wish to adopt a bottom-up approach to AI, wherein we do not outfit an agent with all of its necessary intelligence at the onset, but instead, give it the tools to acquire those skills.
Motivation
More generally, we refer to the bottom-up approach as machine learning.
Learning is the process of an intelligent agent improving performance on some task after making observations about the world.
More concretely, machine learning is the process of discovering / constructing a model from data or experience.
Intuition: humans don't necessarily store all of our waking memories / experiences -- we distill the important parts down into a simplified model of the world that helps us reason, respond, and adapt to it.
These models thus define an input-output module through which the agent can intelligently respond to any given situation.
Inputs can be anything from images to binary variables, and outputs can be any action conceivable for an intelligent agent.
Reasonably, you might ask:
Why do we need to learn some model? Can't we just start with one for our agent?
The answer is largely twofold:
Unanticipated exceptions to a programmer's top-down approach can be adapted-to through learning.
Programmatic difficulty may impede a top-down solution, or it's possible that a programmer simply does not know how to create a top-down approach to a particular problem.
Just as we have done with other problems before this, the set-up of a learning problem is paramount to its success.
Our assumptions about the environment, agent, and a variety of other factors will shape not only the approach to learning that we adopt, but likely the efficacy of that approach as well.
Types of Learning
Virtually every component of an agent can be improved by learning, but depends on the form of learning required for a specific task.
Feedback is integral to the learning process, and determines a metric of success for when an agent has learned something correctly or not. In Machine Learning, feedback is typically categorized into three different types:
I. Unsupervised Learning
Let's start with cases wherein there is an absence of feedback.
Unsupervised learning is that in which no explicit feedback is given, and the agent is left to its own devices to determine potentially useful associations between data points.
Commonly, unsupervised learning involves intelligent clustering, wherein agents are meant to find commonalities between inputs, even though they may not know what commonalities they have detected.
In image clustering, some techniques may group pictures of sunsets together because these images have many orange-red hues arranged in a particular fashion, even though the agent has no concept of "sunsetness"
Spotify learns what songs are commonly grouped together, even though it may not necessarily know all of the traits that unite them in a playlist. Same with Amazon and "commonly bought together" queries.
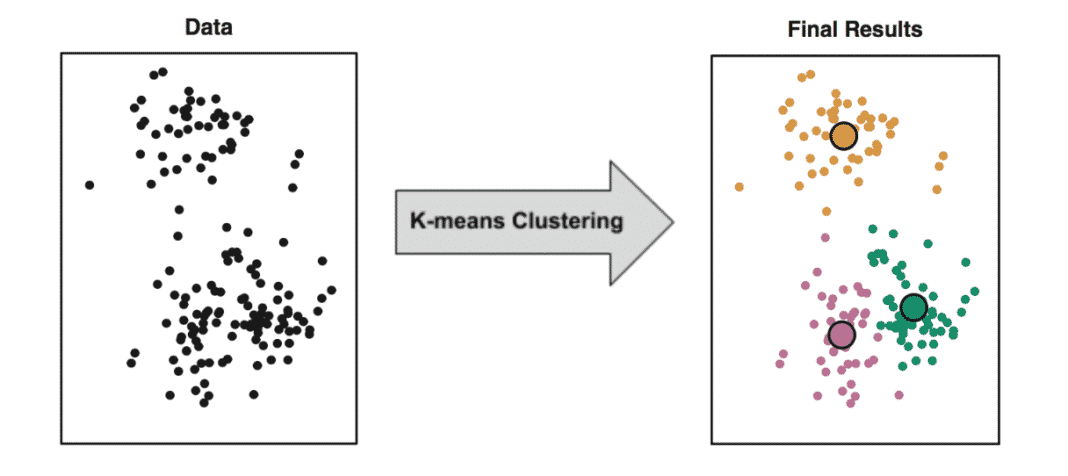
Although an important and vast field, we will not have time to discuss Unsupervised Learning in this course.
II. Reinforcement Learning
When you are training a dog to perform a trick, what technique do you use to capture its attention and attempt to solidify your training?
You give it a treat when it succeeds at the trick!
This same technique applies to many machine learning applications as well.
Reinforcement learning teaches an agent by providing rewards and punishments to respectively encourage and discourage the actions that the agent took leading to that reinforcement.
Returning to our analogy, a dog that receives a treat when it performs a trick on command will be more likely to repeat that action in the future.
Similarly, if it pees on the floor and you scold it, it will be less likely to repee-t that action in the future.
Want to learn more about Reinforcement Learning? Take Cognitive Systems Design in the coming semester!
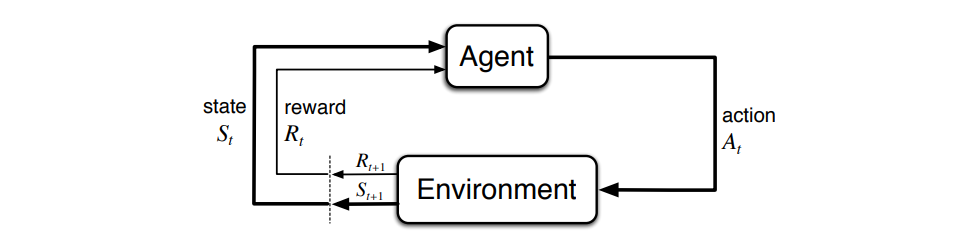
III. Supervised Learning
This is the most "traditional" form of learning wherein an agent's behavior is given specific feedback corresponding to what they should do under what circumstances.
For example, a driving instructor will explicitly tell a student to brake when appropriate, and the student will learn what circumstances demand braking as a result.
Supervised learning agents observe example inputs paired with intended outputs, and attempts to learn the functional mapping from input to output.
This is a category of ML techniques known as "classification" and will be at the center of our discussion for the following weeks!
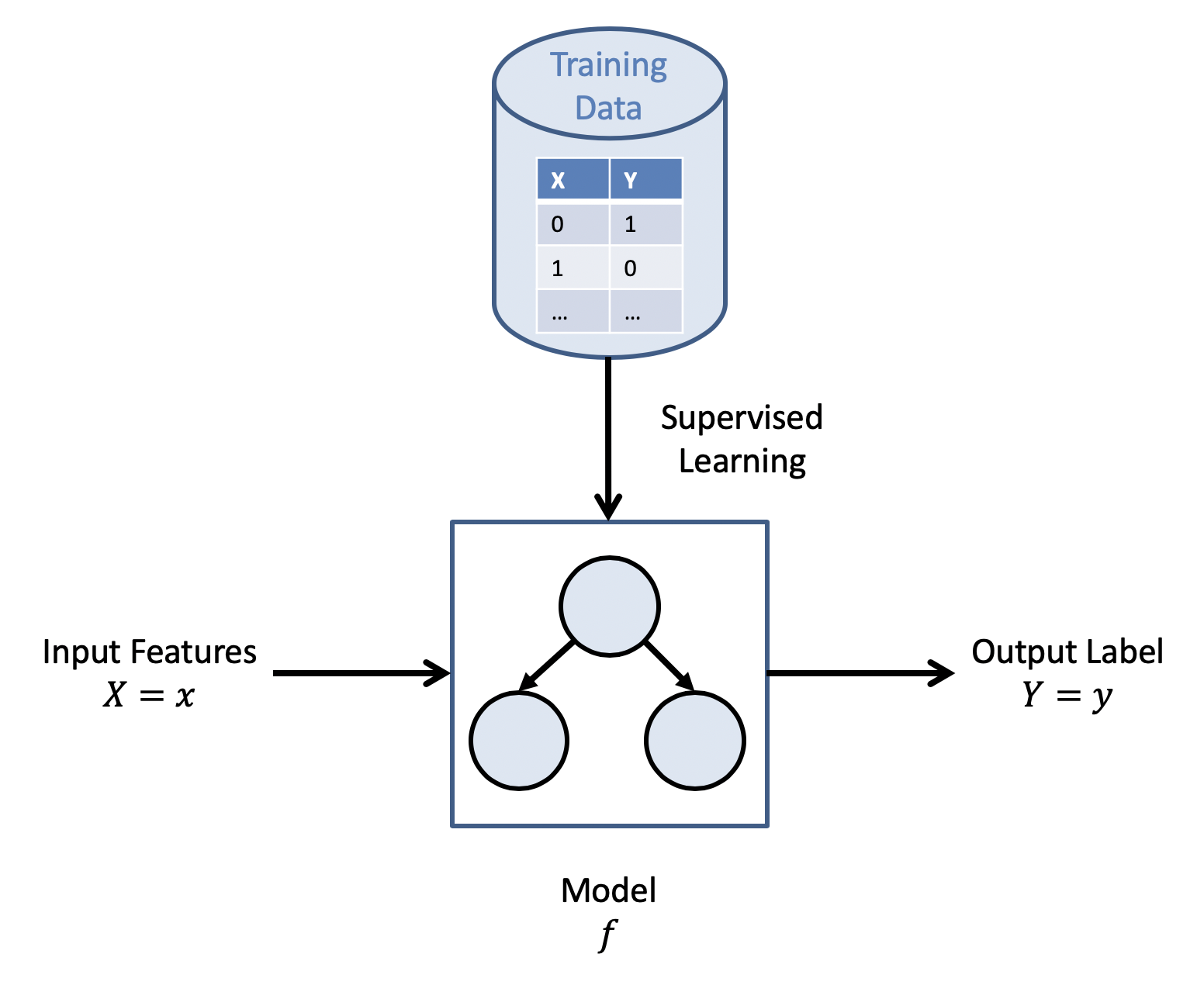
Image credit to me, just so you know I'm not a completely lazy slob.
Note: Although typically referred to in these discrete categories, much machine learning consists of some composite of the above.
Learning from Examples
One of the most fundamental types of learning is that in which we, the programmers, provide our agent with a wide variety of data in some target domain, and expect the learning algorithm to figure out how to act from those examples.
The paradigm of learning from examples stipulates that a learning agent adopts its behavior from some dataset over relevant environmental features.
Features are variables a learning agent attends to as deciding factors for how it should act.
In supervised learning from examples, datasets the agent learn from are called training sets, wherein each data point includes:
Features \(X\), a vector of some number of "inputs" to an agent.
Output \(Y\), corresponding to the intended response to that input.
When the intended output \(Y\) is a discrete quantity (like a set of labels or actions), this learning task is called classification and the output \(Y\) is called a class.
What is it the agent's responsibility to learn from these supervised learning examples?
The assumption is that there is some "true" function \(f\) that maps the input features to their intended outputs, and the agent will be able to approximate this functional relationship: $$f(X) = Y$$
The agent's approximation of this function \(f\) is typically referred to as its model.
Once the agent has approximated \(f\) from the data, it can make autonomous determinations of the output \(Y\) from future presentations of the feature \(X\), typically by way of three steps:
Training occurs using typically ~\(70\%\) of the given dataset, upon which the agent attempts to learn the function mapping features to outputs (like studying for an exam).
Validation occurs on ~\(20\%\) of the given dataset that was not trained upon in an effort to judge how well the agent learned the function, after which it can use its results to retrain (like doing a practice exam).
Hold-Out / Testing occurs on ~\(10\%\) of the dataset, and is used as a final score of the model's efficacy (like taking the actual exam).
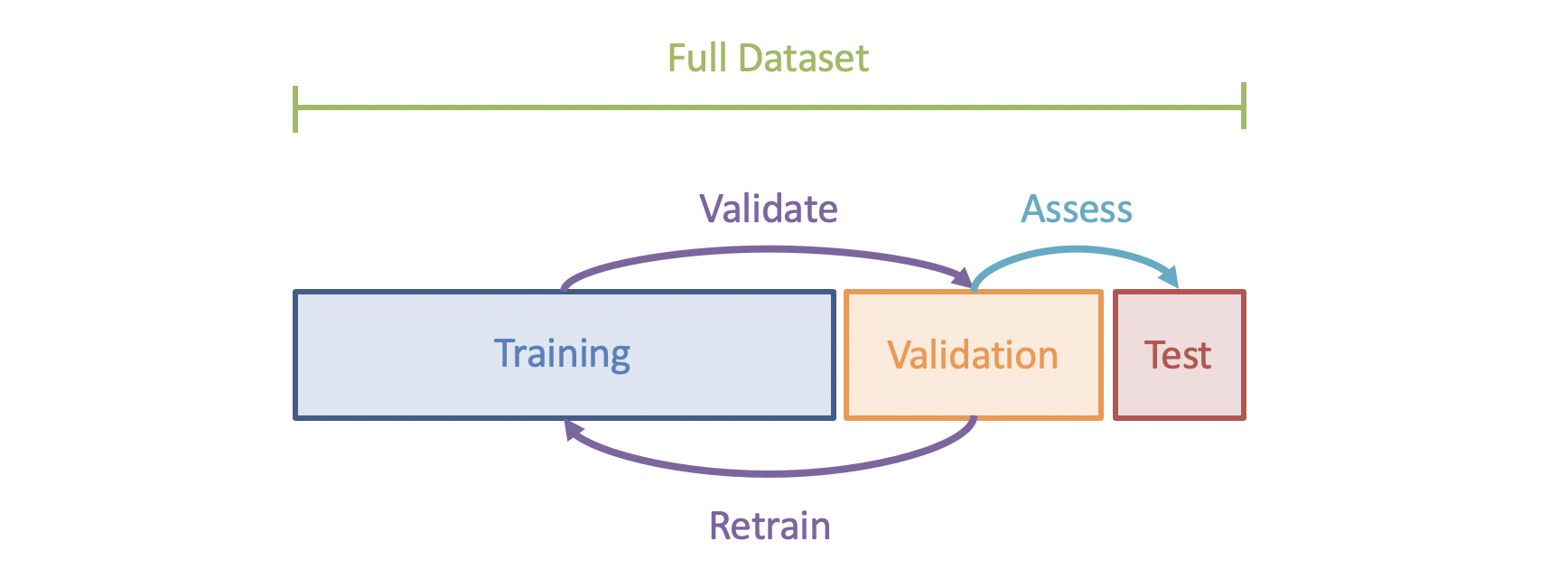
Why is it important to separate supervised learning into these phases?
For the same reason we're not allowed to see the exam before we take it: to make sure that what we've learned while training *generalizes* to examples that we haven't seen before!
Example Dataset
Here is what such a training set might look like on a dataset with 3 binary features and one binary class:
Data Point |
Features |
Outcome |
||
|---|---|---|---|---|
\(X_1\) |
\(X_2\) |
\(X_3\) |
\(Y\) |
|
\(d_1\) |
0 |
1 |
1 |
1 |
\(d_2\) |
1 |
0 |
1 |
0 |
\(d_3\) |
0 |
1 |
1 |
0 |
... |
... |
... |
... |
... |
To translate, data point \(d_1\) says that when the agent sees \(X_1 = 0, X_2 = 1, X_3 = 1\), the result should be \(Y = 1\).
However, for the same features, \(d_3\) says the result should be \(Y = 0\).
If a classification dataset has two or more datapoints that, for the same features \(X\), conflict on what the output should be, how should the agent act if it encounters that feature configuration in production?
It should simply choose the output that maximizes the likelihood of being correct (i.e., for the same features, find the plurality of class labels). tldr: try to be right more often than wrong.
There are many subtleties to this discussion that we'll see in the coming days, but the above gives us a good start!
As such, our agent must be able to learn to act from a dataset in a manner that maximizes the likelihood of it being correct.
List some other examples of supervised classification tasks!