Synchronization
Last time, we looked at some approaches to process scheduling, and noted that some approaches are considered preemptive.
What is the hallmark of a preemptive scheduling algorithm?
It has the potential to interrupt an active process before that process has voluntarily relinquished control.
The potential for a process to be interrupted during certain important operations can produce inconsistencies in a variety of situations.
What are some instances of recent topics we've encountered wherein there is the potential for preemptive scheduling to cause problems?
Shared Resources can be altered and read-from unpredictably, like with interprocess communication (shared memory segments)
Concurrency with multi-threaded applications can be confounded, as was hinted at in our threaded approach to sum-of-sums
As such, we require some tools to enable arbitrary synchronization between parts of tasks that may otherwise be asynchronous.
Process Synchronization involves the tools and mechanisms to ensure the orderly execution of cooperating processes.
Let's start this endeavor by looking at a motivating problem from our past.
The Bounded Buffer: Revisited
The bounded-buffer / producer-consumer problem is one in which two processes share a fixed-size buffer of items in which:
The producer creates items to be consumed in the shared buffer and increments a
countwhen item is produced.The consumer processes / consumes items in the shared buffer and decrements the
countwhen item is consumed.The producer cannot create items if the buffer is full, and the consumer waits for items if the buffer is empty, as tracked by the shared
countvariable.
Pictorially, we can treat the buffer as a circular queue such that both producer and consumer wrap around the BUFFER_SIZE:
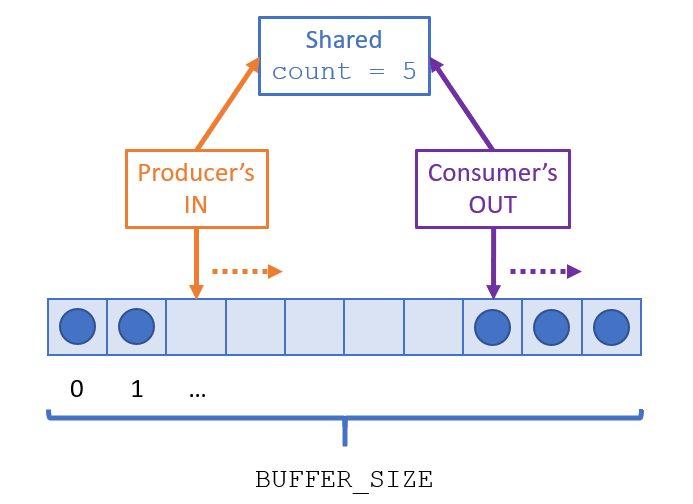
Note: although this is an abstract problem description, it is representative of many synchronization problems in practice, like maintaining a mailbox.
We can see the roles played by producer and consumer in pseudocode:
while (true) {
// Produce the next item
nextProd = production();
while (counter == BUFFER_SIZE)
; // Continuously wait if full
buffer[in] = nextProd;
in = (in + 1) % BUFFER_SIZE;
counter++;
}
|
while (true) {
while (counter == 0)
; // Continuously wait for product
nextCons = buffer[out];
out = (out + 1) % BUFFER_SIZE;
counter--;
// Consume this item
consume(nextCons);
}
|
The problem: although the Producer and Consumer described above operate as intended separately, there are potential pitfalls to them running concurrently.
In particular, consider the counter variable that each manipulates to track the number of items in the buffer.
However, certain statements in source code may not translate to atomic (i.e., single, uninteruptable units of computation) instructions in machine code.
Even statements as innocuous as counter++; may be subject to risk from concurrently executing processes that manipulate counter.
How might the counter++; statement be translated into machine code, manipulating registers?
register1 = counter register1 = register1 + 1 counter = register1
As such, consider that we have a Producer produce an item and a Consumer consume an item roughly around the same time.
A synchronized (i.e., intended) sequence of instructions might look like the following:
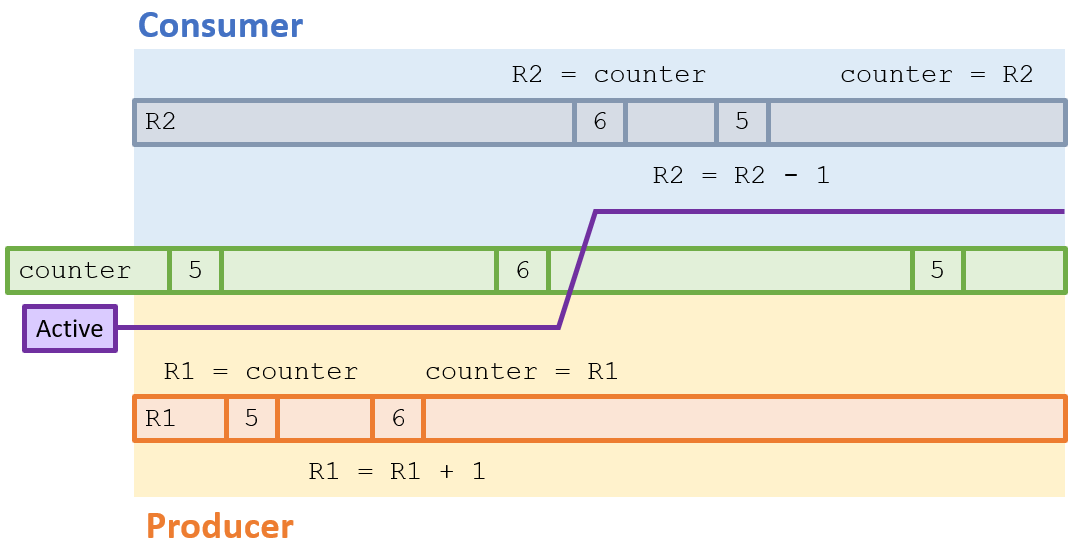
That's all well and good, and is (hopefully) how our threads executed:
... but...
Supposing a preemptive scheduling scheme, is there another possible order in which the instructions may have happened?
Yes! It's possible that a context switch could happen before the producer stores its register in the counter!
Such a divergent case would look like the following:
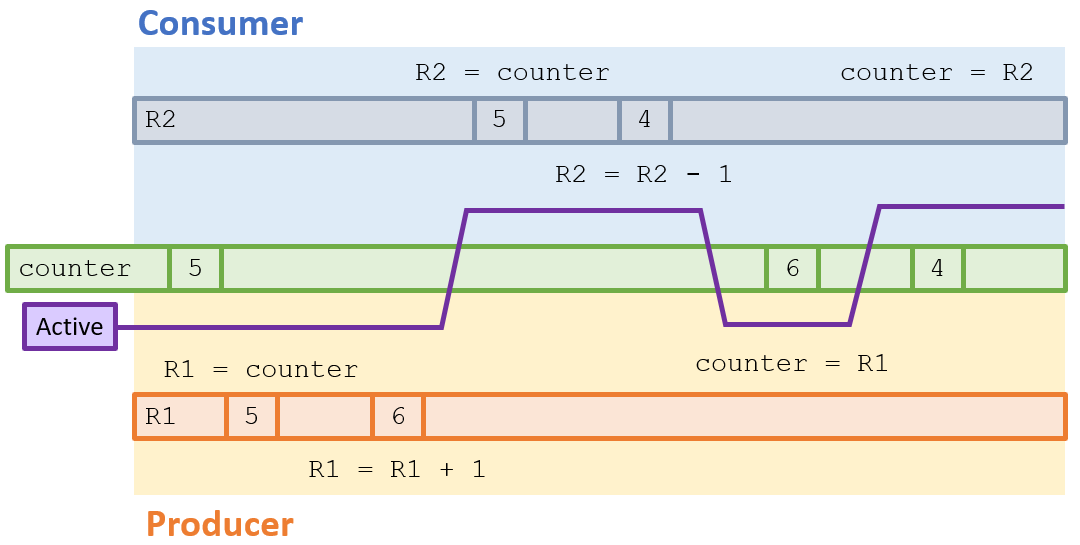
In this scenario, our shared counter would end up with the value 4, which is incorrect!
It is precisely these types of scenarios, called race conditions, that synchronization is meant to aid.
Race Conditions are situations in which the outcome of several cooperative processes depends on the order in which their access of the shared resources occurs.
Race conditions are generally to be avoided, and demand that we start to formalize an approach to synchronization.
The Critical Section Problem
The race condition that manifested in our motivating example was such that key portions of cooperative processes were not allowed to operate atomically.
As such, what we would like to develop is a procedure for ensuring that certain segments of code that are designed to operate atomically are allowed to -- a procedure that begins by identifying such key sections as so-called critical sections.
In a system consisting of \(n\) cooperative processes, \(\{P_1, P_2, ..., P_{n-1}\}\), each will possess a section of code called a critical section which consists of instructions desired to be executed atomically relative to the other processes.
Critical sections are typically those involving manipulations of shared resources, like changing shared variables or writing to a file.
As such, we now face a challenge to implement critical sections as segments that are atomic compared to a process' other cooperative peers, even in the face of a preemptive scheduler that may interrupt them at any time.
The critical-section problem is to design a protocol that processes can use to cooperate such that:
No two processes are executing their critical sections at the same time
Each process must request permission to enter its critical section and indicate when it has completed it
Because of this problem specification, processes with critical sections typically have accompanying sections with certain semantics that surround the critical ones.
Prototypical processes attempting to solve the critical section problem possess several components:
Entry section: responsible for permitting entrance into the critical section
Critical section: with code intended to be executed without interruption from cooperating processes
Exit section: responsible for signalling the conclusion of the critical section
Remainder section: everything following the exit.
Depicting these components:

Why is the above surrounded in a do-while loop? How does this relate to our critical section problem?
If the process is temporarily blocked from its critical section (i.e., is not allowed entry at the entry section), it must try again until it is allowed entrance.
Finally, just as we had some metrics of success for good scheduling algorithms, so too must we analyze some metrics of success for good solutions to the critical section problem.
In particular, solutions to the critical section problem must exhibit the following properties:
Mutual Exclusion: no critical sections overlap
Progress (Deadlock-free): at least one willing process is given access to its critical section at any time
Bounded waiting (Lockout-free): every willing process is eventually given access to its critical section
With these criteria in mind, we'll have to wait until next time to see how to "solve" the critical section problem!