Main Memory
Earlier in the class we examined the memory hierarchy, establishing which tiers were supported by which others.
The hierarchy was important because the CPU only has direct access to its registers, and so how data moved to and from the registers, cache, and RAM is also important from a processing standpoint.
However, from our previous section detailing process management, we spoke abstractly about a process' memory image, meaning the contents of a particular process in RAM including its data and instructions.
What we didn't discuss is how these images are organized in RAM, and how both OS and CPU view RAM and its contents.
This will the topic of the next couple of weeks!
Process Memory Organization
Why is it important that a process be unable to view or modify memory allocated to another process?
Chiefly, security and errorproofing!
It would be absolute chaos if we allowed processes to modify the memory images of one another (or even the OS!) without some system of checks and balances.
As such, one of the first responsibilities of an OS' Main Memory management is to ensure that each process is given its own memory space that (apart from any volunteered sharing via IPC) cannot be accessed by another user process.
A process' logical address space is defined as a range of addresses as specified by two CPU registers:
Base Register holds the smallest address allocated to a process.
Limit Register holds the number of addresses above the base address allocated to a process such that its address space is within the range: [base, base + limit - 1].
Pictorially, this looks like:
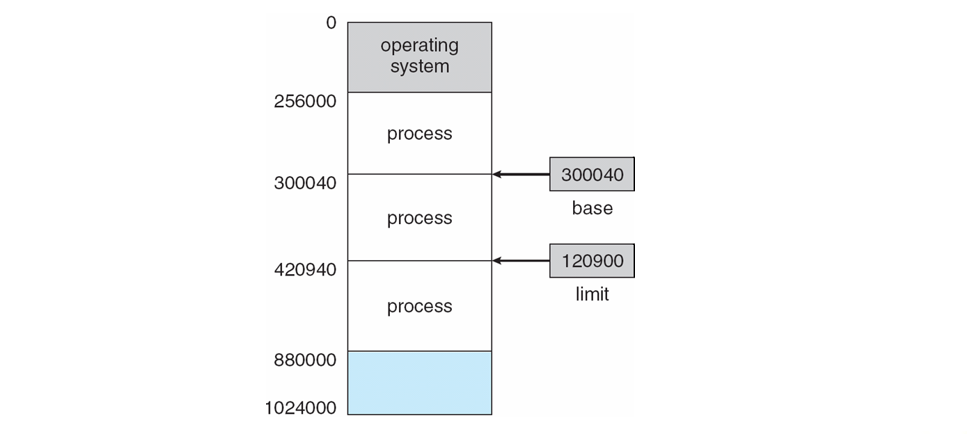
Knowing the range of allocated addresses thus allows an operating system to ensure secure memory access.
Which process' memory addresses should be screened for illegal access, how would illegal access be detected, and what should the OS do in response?
Only user processes need to have memory accesses checked (since the kernel can do whatever it wants), illegal accesses can be checked via a procedure like the below, and in the case of an illegal access, an exception is generated.
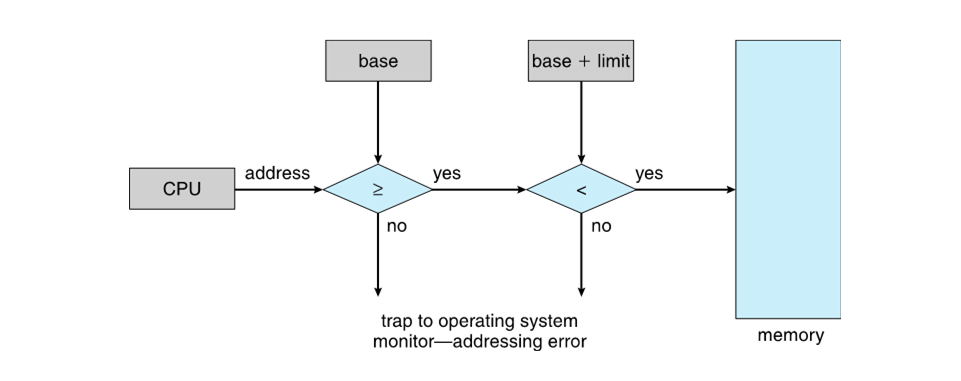
As another security measure, how do you think we prevent user programs from modifying the base and limit registers?
Make their modification privileged instructions such that they can only be loaded in kernel mode (which is done in practice).
Now that we see how a process' address' are "carved out" (at least conceptually), we should consider: how do the CPU and processes themselves "see" addresses and how do we manage them?
Swapping
We should address (heh) a very prominent concern when it comes to managing main memory:
Suppose we have 4GB of RAM and processes with memory images totaling 8GB in size; what should we do?
Move some of those memory images into a "temporary" storage (hey, why not the tier below RAM in the memory hierarchy?), keeping only those processes that are executing or next scheduled to be executing in RAM!
Towards this end, the OS will maintain an input queue consisting of those processes that are in the ready state, but whose memory image has been offloaded into secondary storage referred to as a backing store.
The procedure of exchanging processes from the backing store into RAM and vice versa is called swapping.
As such, when a process has been scheduled, but may exist in the input queue, we simply copy it from secondary storage into RAM.
The opposite is true: when a process is terminated, that space becomes available for other processes to be loaded into RAM.
Pictorially:
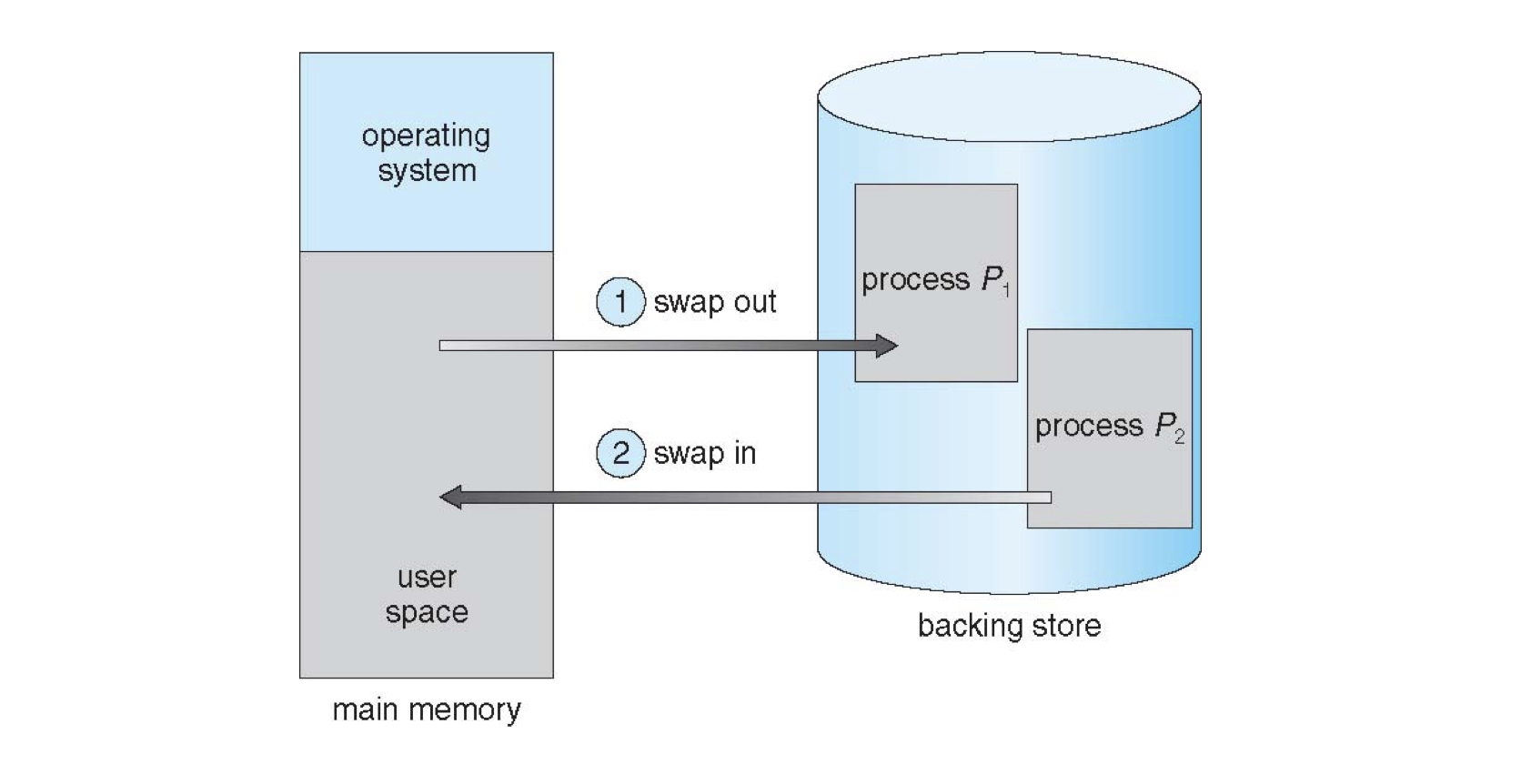
Why does this procedure make context switches a bigger efficiency concern than we previously considered?
Because the latency of data access between secondary storage and RAM can be extremely costly, on the order of 1,000,000x slower than accesses between RAM and the cache.
Moreover, there is some latency overhead for older spinning hard-disks wherein the proper memory segments to read from / write to must be sought as well.
To get a handle for this:
Suppose we have a memory image that is \(200MB\) and our HD can transfer \(50MB/s\) with an \(8ms\) latency overhead; how long will a single swap take for this process?
A simple calculation: $$\text{Transfer Time} = \frac{\text{Size of Image}}{\text{Transfer Rate}} + \text{Latency}$$
So in our case, this translates to: $$\text{Transfer Time} = \frac{200 MB}{50 MB / s} + 8 ms = 4008ms \approx 4s$$
That is a long time for a single process!
Brainstorm: given that most of this time is spent for the actual transfer (in proportion to size of the image), what are some ways an OS might be able to reduce this lag?
Chop up the memory image and only bother swapping what is necessary for the process at the moment!
Few OS' use the standard notion of swapping mentioned above, but variants are often employed, which we will consider in the next lecture... in the meantime, let's focus on the mapping of a process' memory to RAM
How should a process' addresses be decided when it is copied into RAM?
Address Binding
When we write source code, do we specify the specific memory addresses in RAM that we wish to store our data within? Why or why not?
No! Of course not, that would be dangerous and wasteful since it would be impossible to predict what addresses were already in use by another process.
Instead, we express memory in terms of symbolic pointers, and then expect that these are bound to "real" addresses by the OS.
In general, binding can be accomplished at any stage of the execution process:
1. Compile-Time Binding binds symbolic memory references to exact logical addresses during compilation.
Although this was done in the early days of MS-DOS, for the reasons above, it is completely outmoded in modern, multi-processor user applications.
As such, we can instead try something like:
2. Load-Time Binding binds symbolic memory references to exact logical addresses once the process is loaded into RAM.
This approach yields relocatable code from the compilation process, in which the base address of a process may change without fault, but suffers from a key shortcoming:
What is the shortcoming of load-time binding?
Once the program is loaded into RAM, it cannot be moved to accommodate other processes.
This is more of an issue that we will discuss next time and is related to memory fragmentation (stay tuned).
Finally, the third option is what is used in practice:
3. Execution-time Binding binds symbolic memory references to exact logical addresses during execution, which is enabled by special hardware.
Execution time binding is supported by a hardware component known as the Memory Management Unit (MMU) that is responsible for mapping a logical address (seen by the CPU and user processes in source) to a physicial address in the RAM hardware itself.
A key part of this process is the configuration of a relocation register aboard the MMU such that its value is always added to a logical address to map to a physical one in what is known as dynamic relocation.
Pictorially, this gives us the following:
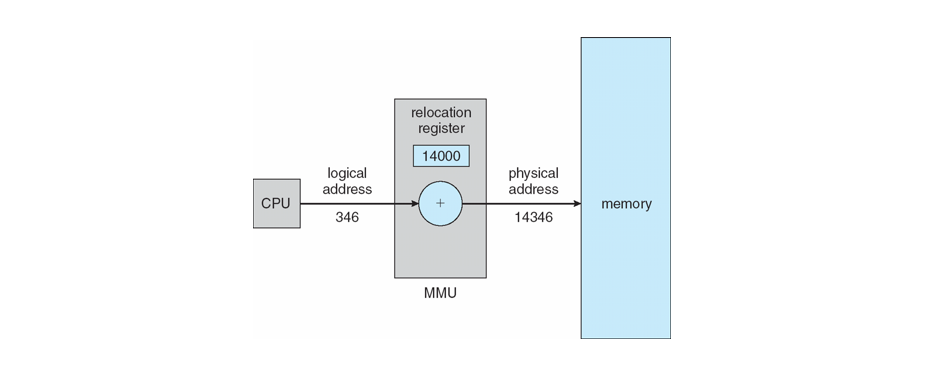
Next time, we'll investigate this distinction between the logical and physical address space, and continue with the mechanics of memory organization!