Paging (Continued)
Last time, we looked at the paging memory allocation scheme and juxtaposed it with the older contiguous allocation approach.
Today, we'll expand on the paging effort and see how it leads us to a clean division between the logical and physical address spaces while diving into some of the finer implementation details.
Sharing
One of the easily-implemented applications for paging is the ability to share pages between processes.
Though this can be complicated if the shared memory is intended to be modifiable between processes, it is straightforward for read-only sections, like text sections between threads:
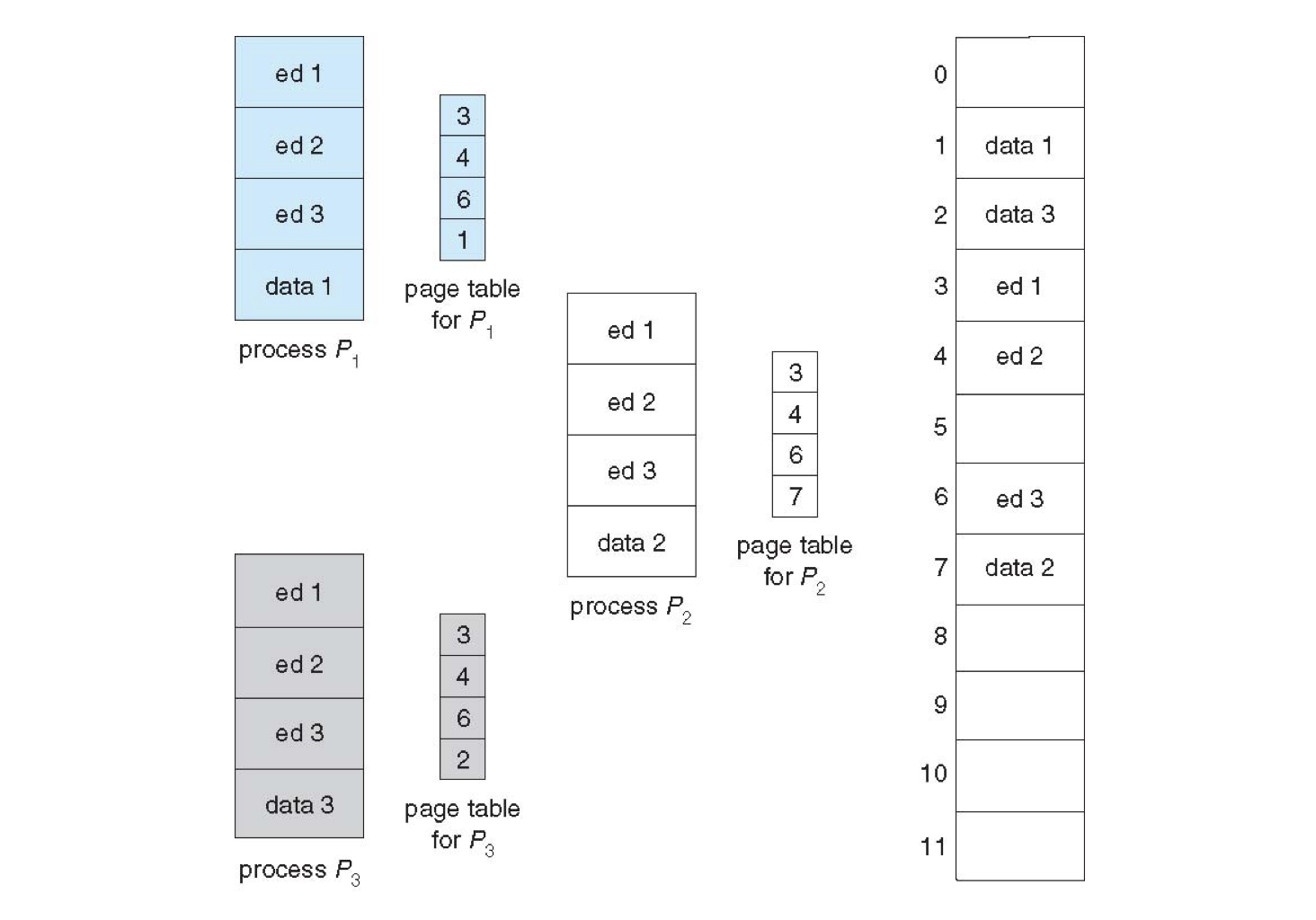
Reentrant (Pure) Code is intended to be read-only and can be shared between processes without risk of any modification.
Observe three processes below that need only refer to shared pure code pages \(ed_1, ed_2, ed_3\).
Protection
In a previous lecture, we considered how the OS could ensure that no process attempted to access the memory associated with another process' partition.
In the contiguous allocation scheme, what mechanism did we use to ensure no illegal memory access?
A base and limit register that established the bounds of every process image, and could only be set in kernel mode.
Followup: will this approach work if we used a paging allocation scheme? Why or why not?
Plainly, no; providing a single valid range will only be useful for detecting valid access with contiguous partitions.
How, then, might we track whether a logical memory address is valid or invalid for the accessing process?
Track valid ranges with respect to the page table!
Towards the ability to provide protection via the page table, we can, by analogy, maintain several mechanisms to ensure that no process illegally accesses pages associated with others.
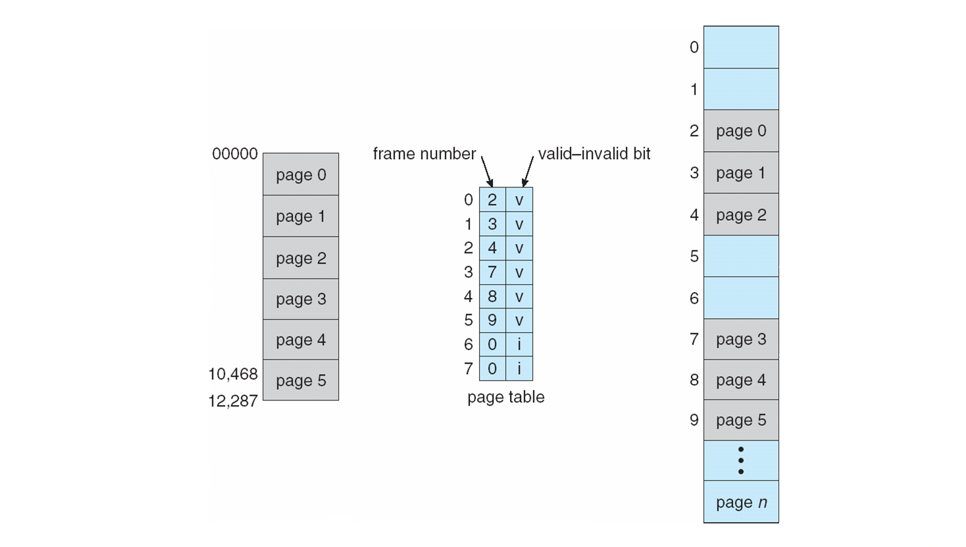
The page-table length register (PTLR) is used to track... well... the length of the page table for a given process.
Quite simply, if a process attempts to access a logical address that is beyond the length of the page table, a trap / exception is generated and sent to the OS to handle.
Another subtle concern may be that pages within the table are no longer validly accessible during the course of a process' lifespan (and for other important reasons we will discuss shortly).
To prevent intra-table illegal accesses, we can add another bit of protection (literally) to the page table that determines whether a page within the proper table length is still valid.
Page tables can maintain a valid-invalid bit for each page that, if invalid, will also generate a trap / exception to the OS.
Pictorially, we might have something that looks like the following:
The valid / invalid bit begs an interesting question: how could a page be considered "invalid" and why would it be useful to track this?
To motivate the answer, consider: in order to execute a process' instructions via the CPU, those instructions must first be loaded into RAM... however...
Does that mean that the all of the pages for a process need to be in RAM at once?
No! We can have pages loaded into RAM as they are needed!
This is the approach we'll examine next!
Virtual Memory
Last time, we saw the beginning distinctions between virtual and physical memory, and today, we'll dive deeper into the prior. For review:
Virtual memory is the programmer's perspective of memory, generally viewed as a contiguous block.
As we've seen, using paging allows the programmer to continue viewing memory as a contiguous block while avoiding fragmentation once it is translated into physical memory.
Motivation
Even with paging, however, we have considered that a process would still have all of its pages loaded into RAM at once, but what are some reasons this may not be necessary?
There are a variety of cases:
Error handling code: is seldom called by a program, and need not be loaded into RAM if it is not to be employed.
Over-declaring memory: arrays that are declared with dimensions 100 x 100 may only, in practice, employ 10 x 10 of that space -- no reason to load that which is not used!
If we devise a means of allowing processes to execute without being fully loaded into RAM, what are some tangible benefits?
We would enjoy both performance and memory efficiency benefits because of:
Lack of Constraint by Physical Memory: if a process' image requires 10GB of space, but we only have 8GB of RAM, we need only load the pages that are currently being executed or are relevant to the current execution.
Enhanced parallelism: since each user program would take less of RAM to execute, more processes can exist in RAM at the same time (to make context switches more efficient).
Fewer I/O Operations: since swap-time is proportional to the amount of memory being swapped, this is reduced, and so processes will run more quickly.
Sparse Addressing
We can revisit the programmer's mental model of a process' memory image, and start to consider how it can be interpreted using paging.
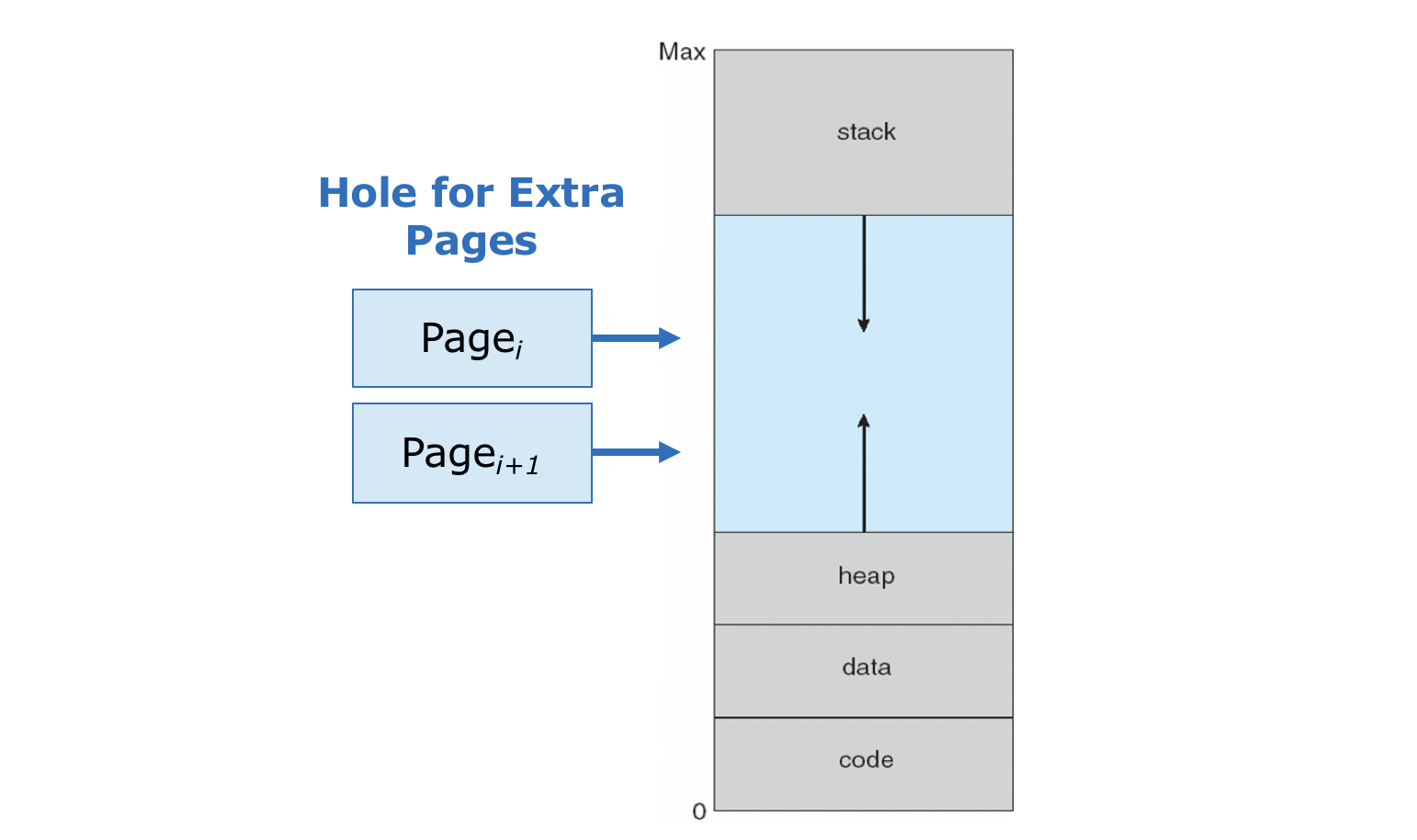
In particular, what we glossed over previously was how to manage the free space in between the stack and heap, but this is really just a hole that can be mapped to physical memory at will.
A virtual addressing schema that includes holes is called a sparse address space since holes can be filled dynamically.
Sparse addressing comes with two chief benefits, as illustrated below:
Benefit 1 - Easy Dynamic Allocation: as a process dynamically allocates more memory, additional pages can be added to the free the space to accommodate its needs without having to shift all memory contents as well.
This amounts to simple "surgeries" on the page table:
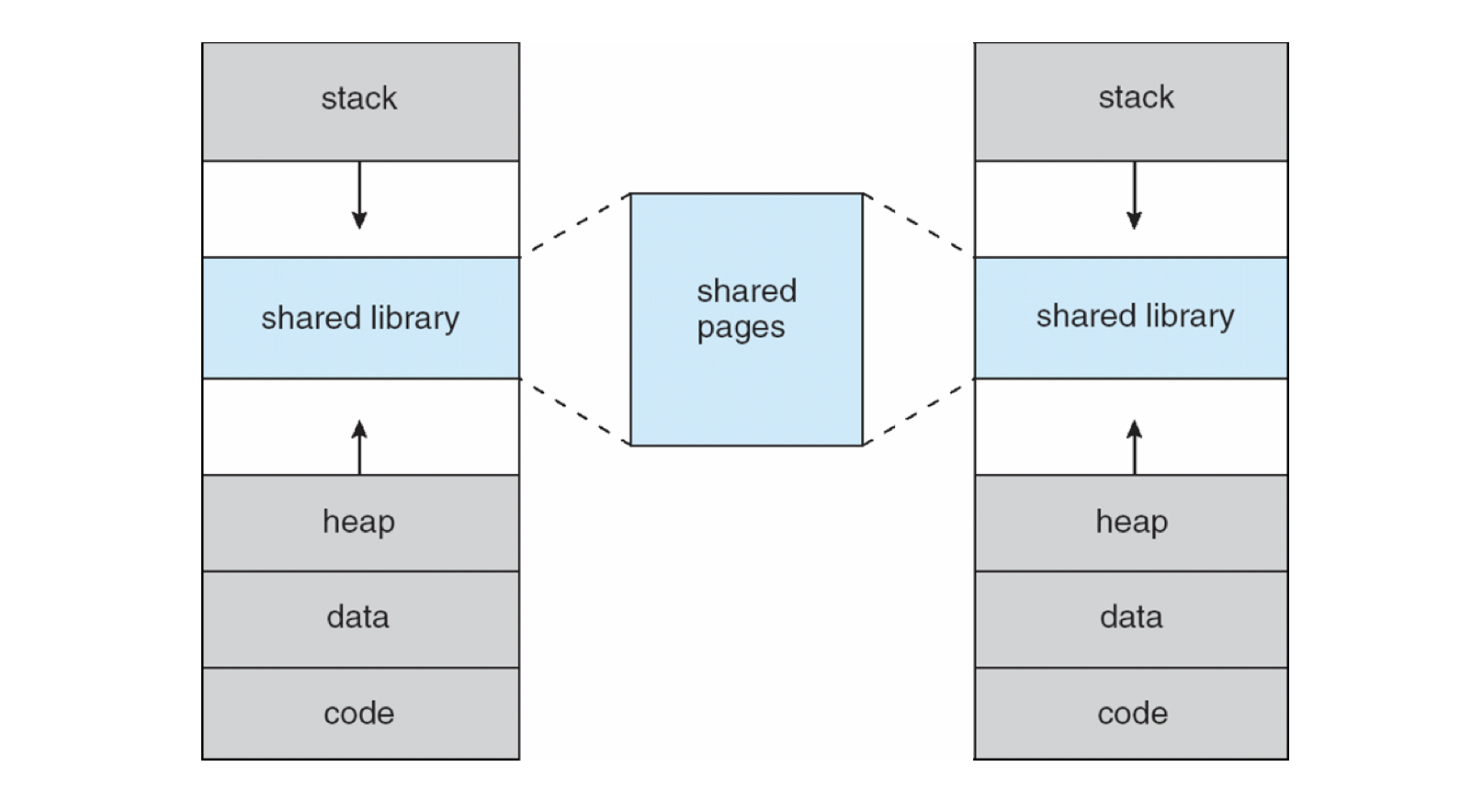
Benefit 2 - Easily Shared Pages: shared memory, like system libraries, can also be inserted into the free space and grown as additional inclusions are made.
These are noble objectives to accomplish, and the benefits are tangible, but how do we implement them?
Demand Paging
The technique to only load process pages that are needed during execution is called demand paging such that:
A pager is responsible for swapping individual pages to and from the backing store (unlike a swapper, which applies only to contiguous allocation schemes).
A page that is never needed (i.e., demanded) during execution is never "paged" into RAM.
One cute perspective is that a pager is a "lazy swapper" since it only swaps those pages in that are demanded.
Of course, we still need some tracking mechanism to determine when a page needs to be swapped in. Luckily, we already have such a mechanism:
What mechanism do we have in-hand that would allow us to determine whether or not a page in virtual memory has already been loaded and mapped to a frame in physical memory?
The valid-invalid bit in the page table!
This might appear to be an overloading of purpose for the valid-invalid bit, but recall that when the CPU encounters a page marked as invalid, it gives the OS a chance to decide what to do!
It is thus the responsibility of the OS to determine what should happen when a page fault has occurred.
A Page Fault is an exception that occurs when a page access is attempted but the valid-invalid bit is invalid. The OS will then make a determining response:
If the page is indeed invalid (i.e., not a valid page in the logical address space), this is an illegal memory access, and so the process is terminated.
If the page is actually valid, but simply has not been loaded into physical memory, the pager is invoked to swap the page in.
This process looks like the following, with steps explained below:
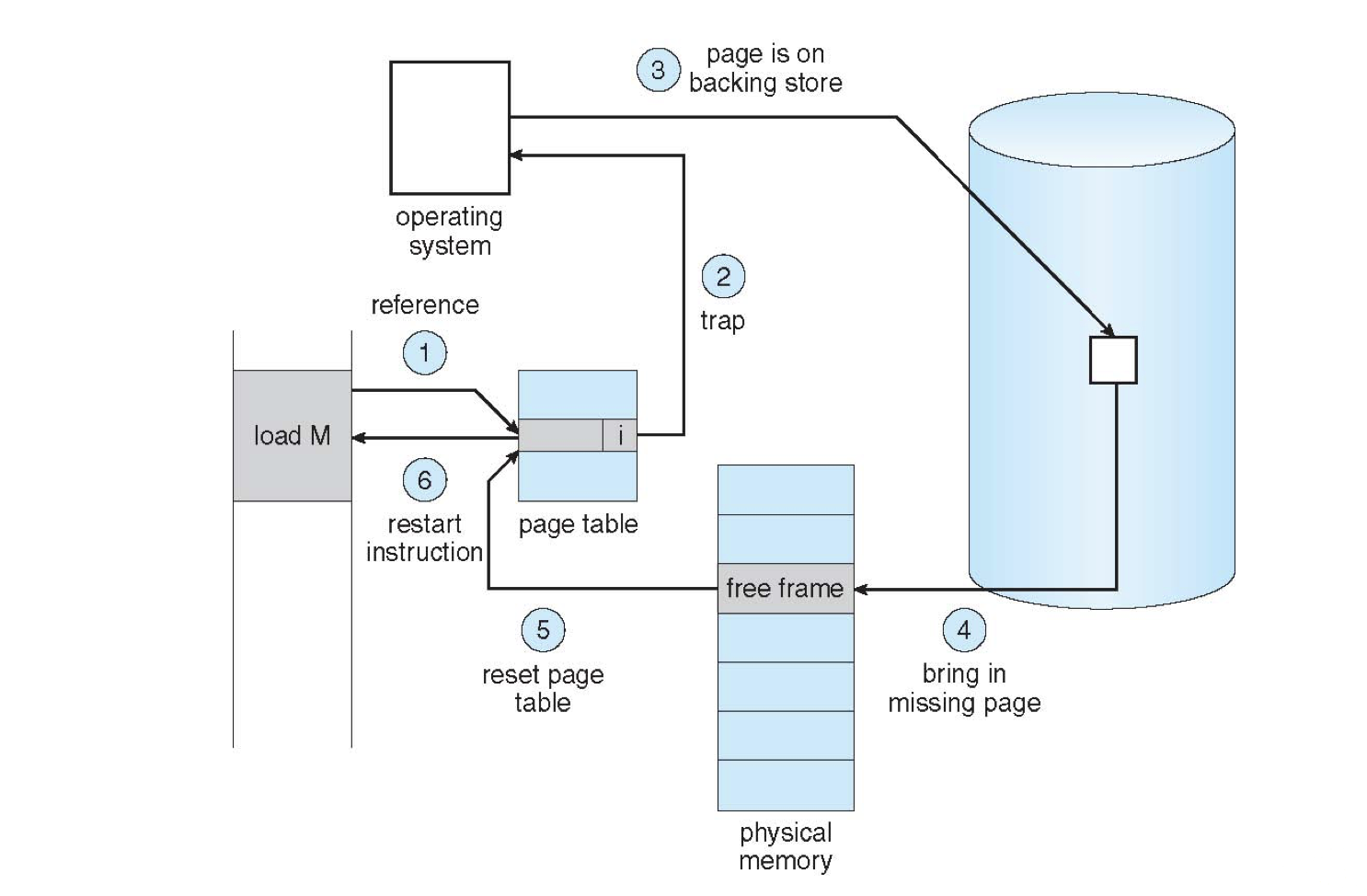
When a logical address is converted to physical, the valid-invalid bit is checked on that corresponding page.
In the invalid case, the OS handles the trap / exception and determines if the process should be terminated or handed to the pager.
In the case where the page is valid but must be swapped in, the pager finds it in the backing store.
Once located, the page is swapped into a free frame in RAM via the free-frame list and an I/O operation.
Once the I/O operation is complete, the page table is updated to indicate that the page is now valid.
The instruction is re-run with the now-loaded page.
Performance Analysis
Plainly, because I/O is involved in this process, we would like to minimize page faults; just to see how damaging to performance they can be, we can assess the performance of demand paging.
The effective access time (EAT) is a probabilistic analysis of the likelihood and cost of a page fault, and is computed by the equation: $$EAT = (1 - p) * ma + p * PFT$$ ...for \(p\) = probability of a page fault, \(ma\) = memory access time, and \(PFT\) = page fault time.
Rather than have you simply plug in values for this, we can see that the objective of good paging scheme will be to minimize the probability of page faults, given that memory access is
In pure demand paging, a page is never swapped in until it is requested.
Is pure demand paging a good paging scheme? Why or why not?
No! Because the probability of page fault is essentially maximized under this scheme, we will be making many interrupts and many small, costly I/O requests.
Can you suggest an alternative to pure demand paging that might improve our performance?
Try to load pages that are likely to be used together, thus defining a locality model of execution.
Because of locality of reference, pagers can swap-in proximal pages when a page fault occurs with the intent of reducing the probability that a future one will occur.
Just how this is accomplished will be a topic of our next class -- stay tuned!