Introduction to File Systems
This lecture will serve as an introduction to file system organization; implementations and greater detail for FS's are covered in the last part of this class.
Put on your safari (not the browser, i.e.) hats everyone, because today we start exploring a file system from a CLI view!
Let's start out with a fundamental overview of what, precisely, we're exploring.
Brief Intro to Files
What is a file?
A file is simply a collection of data (text, images, etc.) stored in some memory location with a unique identifying name.
Plainly, it is important that we assign unique identifiers to each file on a storage medium lest there be ambiguity for common file operations.
Files are simply abstract data types in which data is organized according to the file type (e.g., .txt, .png, ...) and the OS supports six primitive file-manipulating operations.
Create a file: space for the file is reserved on the storage medium.
Writing to a file: adds data to the file.
Reading from a file: retrieves data from a file.
Repositioning within a file: seeks a location of specific data within a file.
Deleting a file: releasing storage memory associated with the file.
Truncating a file: removing data from a file.
How could the rename file operation be implemented in terms of the above, primitive operations?
Create a file with the new name, read from the old, write to the new, delete the old.
Brief Intro to File Systems
Given our requirement that files each possess a unique name to support the OS's basic file operations without ambiguity, what are the problems of storing files in one giant folder?
(1) Unique name violations would be rampant and difficult to maintain, (2) user-unfriendly, and organizationally poor -- would be impossible to find anything!
To combat these problems, we need a procedural means of organizing and storing files.
A file system formalization defines the procedures and data structures used to organize and store files on a disk.
Just how our file system organizes files will come with all of the performance benefits and drawbacks of the data structure that we use to organize them!
What is the typical way that modern file systems organize files? What abstract mechanic does it use?
"Folders" or, more generally, directories
As such, file systems organize the data into files whose locations are specified by the directory structure.
A directory structure is responsible for organizing file locations, including operations like listing and finding file locations.
Most directories can be nested to establish a hierarchy of increasingly specific file locations.
What data structure can be used to represent a file hierarchy of nested directories?
A tree!
Here's an example with sketched directories (orange) and files (blue) [and don't ask what's in Secret.txt].
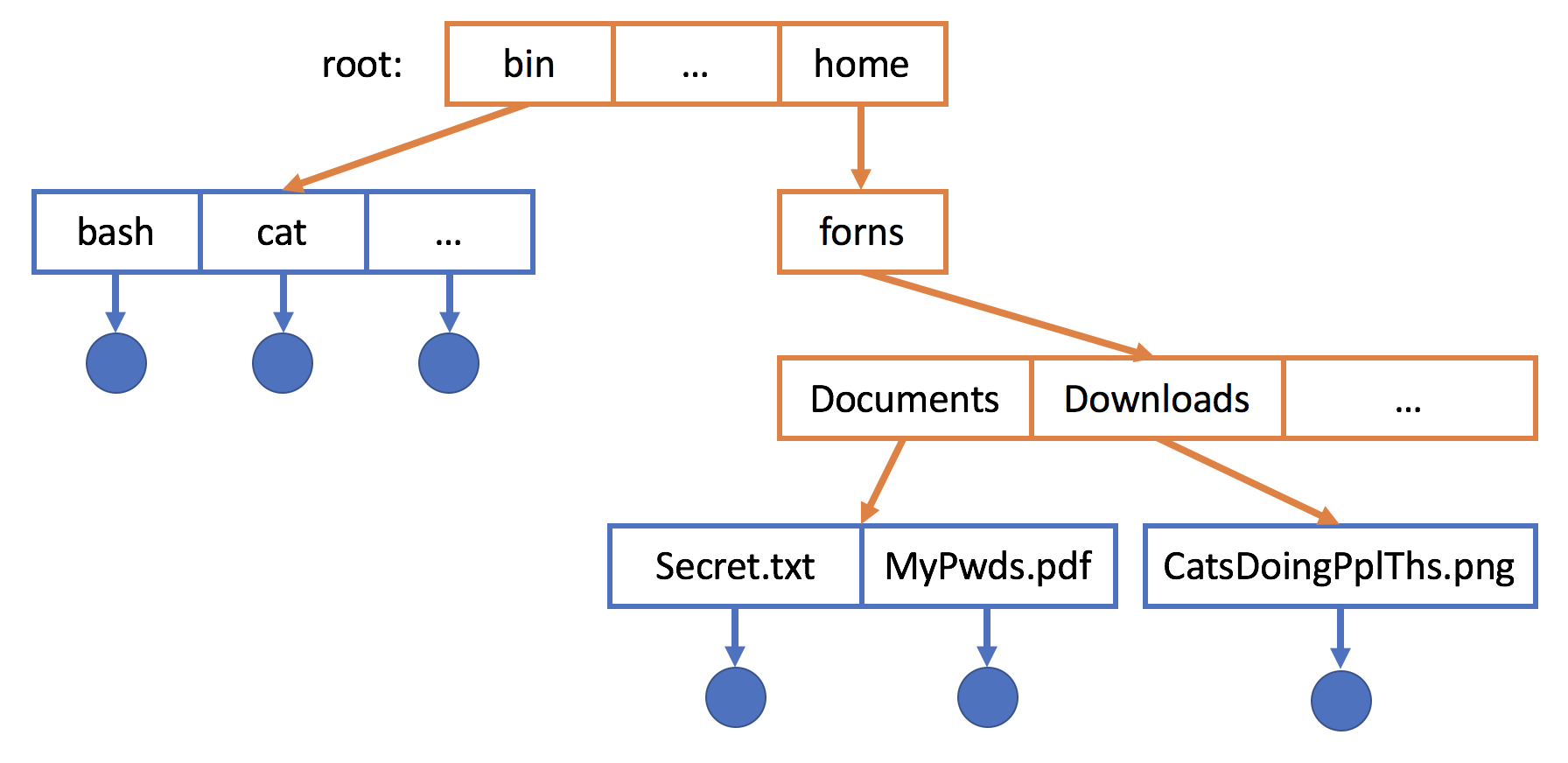
Using this tree-structured directory, we can see a lot of analogies between the tree ADT vocabulary and those we commonly use in file systems:
The root is both the top level of the directory and the name of the super-user (user without access restrictions) in most Unix systems, since they have access to all system commands and files.
A file path is the sequence of directories from the root to the directory containing the file, as punctuated by the file name.
As such, all files are leaves in the directory structure, and all directories are internal nodes.
Though the tree directory structure provides a nice hierarchical organization of files, what is one big drawback (given the semantics of a tree).
Trees demand that a unique path exists from the root to any given node, but we may sometimes wish to share files between users (e.g., for collaboration or not needing to maintain separate copies of shared files).
Common sub-directories can be shared between users, but at this point, our organizational structure is no longer a tree...
What type of a file system structure would we have if we allow for subdirectories and files to be referenced from two separate locations?
A graph!
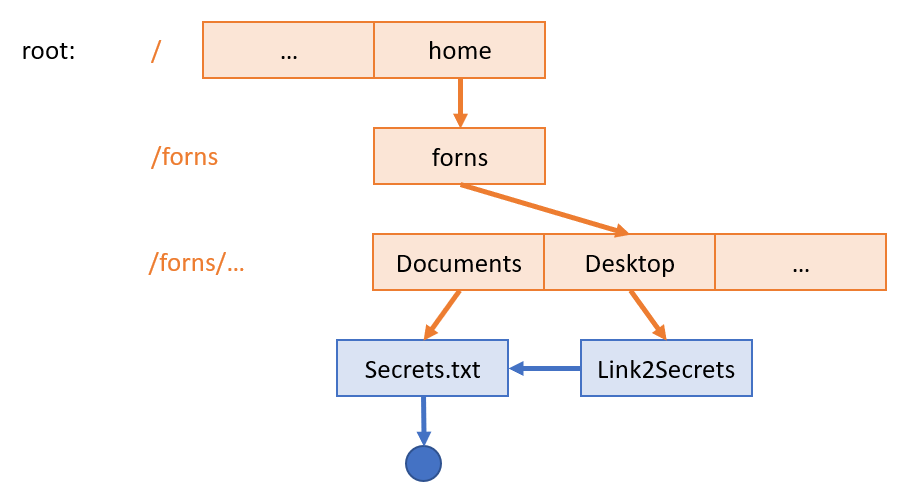
Graph directory structures allow for files and directories to be referenced by links.
Importantly, in Graph structures, only 1 version of a given file or directory exists on the disk, but can be referenced from multiple locations.
Most Unix and Windows variants employ a graphical file system using symbolic links, though the underlying file organization is still a tree.
A link is simply a file pointer that refers to another file or directory; symbolic links are those that will remain even if the file referred to is deleted.
Replicate the following link structure in your FS, then delete Secret.txt and find out what happens to the link.
Graphical file systems are more expressive than tree ones, but what extra challenges do they present? In particular, what operations of a FS might be more difficult?
Among other operations, searching for files is more difficult if links can create cycles in the graph. Many Graphical FS's will exclude links in the search operation to maintain a Directed Acyclic Graph (DAG) semantic.
Exploring the File System
Now that we have a gist knowledge for how a FS is structured, and have viewed some common operations from a GUI, let's start the exploration anew from bash.
Disclaimer: much of the below may seem rudimentary for those who have used a CLI before, but most students tend to learn at least a thing or two from the agility tips!
To begin a bash session, find the Terminal application in Ubuntu -- this provides a GUI (the window) to the CLI (bash), in which the remainder of interaction occurs.
Bash interaction follows several simple steps:
The user types a command, and hits Enter / Return once ready to execute
The computer executes the command, and provides any feedback relevant (NB., many commands, when successfully executed, provide no feedback).
The computer returns control to the user, showing another prompt in which it is ready to obtain another command.
Let's start our journey by exploring the file system's directory structure.
Directories via CLI's
Just like you can explore directories in GUI's by double-clicking on folders and seeing their contents, bash commands are given relative to what is called the working directory.
The working directory (WD) is the bash prompt's current focus; all commands are given relative to the WD.
The pwd (print working directory) command prints slash-separated directories where each slash represents a sub-directory in Unix variants, and typically backslashes in Windows flavors.
Most newly-started bash prompts will begin at the user's home directory, something like /home/forns.
So how do we see what files are currently within the working directory?
The ls (list files) command displays all files and directories in the current working directory.
Many commands have additional parameters that can be specified to change their behavior, usually of the format -X <arg> where X is the parameter name.
To see whether files are directories (/), executables (*), or links (@), we can specify this using the parameterized ls -F
Of course, seeing the current directory and its contents are but the tip of the FS iceberg; plainly we should also be equipped to navigate it!
To navigate the directory structure, we should first discuss how to think about paths in bash.
Absolute paths are locations specified from the root to a particular sub-directory, and will refer to the same location regardless of where they are specified.
In Unix variants, an absolute path typically starts with a slash (/), in Windows, we typically specify a drive letter (C:).
Why would it be a pain to refer to every location by its absolute path? Do we have a shortcut at our disposal?
Absolute paths are explicit but often cumbersome; it would be a pain to list the directory of something that was simply in a sub-directory of the working directory all the way from the root. Let's use the WD as a checkpoint instead!
Toward this goal, we might specify a relative path.
Relative paths are locations specified relative to a sub-directory. Most relative paths are "rooted" in the current working directory.
Relative paths use a variety of special symbols to denote key relations:
Symbol |
Refers to |
|---|---|
. |
Current directory |
.. |
Parent directory |
~ |
Home directory |
With these two primary ways to distinguish paths, we can now see how to change the current working directory:
The cd <path> (change directory) command changes the current working directory to the given path (where path is either absolute or relative to the current WD).
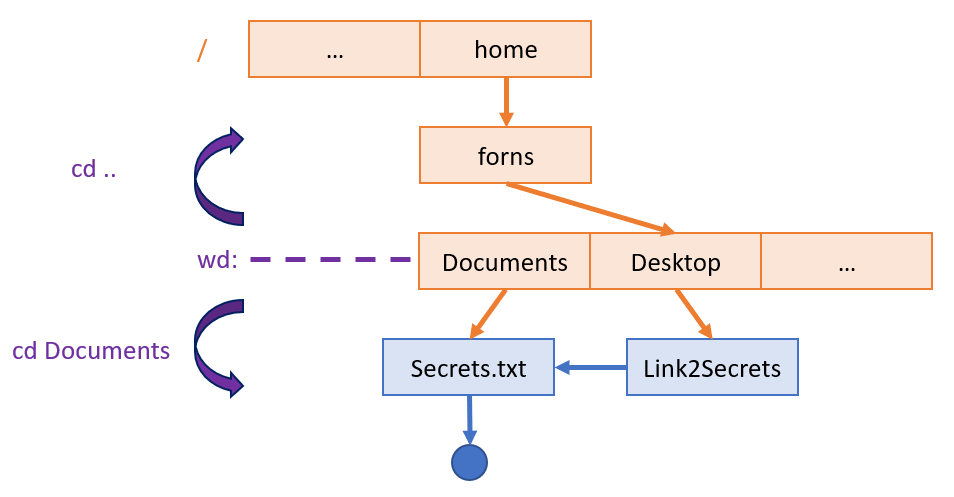
Try the following cd commands, and observe the changes to the working directory via pwd.
cd Downloads
cd ..
cd Documents
cd ~
cd ../..
cd /home/forns
To visualize these relative path commands:
CLI Agility
As we all know (or all are?), programmers are lazy, and if you thought relative paths were already a time saver, we can do even better!
In most CLI's, hitting the Tab key once will auto-complete a command or path if what you've already typed is a prefix of one command or path, and hitting it twice will return a list
of completions.
Try using Tab to autocomplete a variety of commands and paths.
Often times, we are also forgetful and need to recall a command we used in the (in my case, not so distant) past.
The history command lists all recently entered bash commands.
You can use the Up and Down arrow keys to navigate through past commands and re-enter them.
Built-In Commands vs. External Programs
Many of the bash commands introduced today are actually external programs that are being invoked via the CLI, but some are intrinsic to the shell itself.
Builtin commands are those that are part of the shell's source whereas executables are programs written in files stored on the system.
The which <command> command will return a path to an executable if the command is not a builtin, except in some circumstances*.
* Sometimes, a builtin command has an executable corresponding to it, but it is the builtin implementation that is used.
Note: the above are only a small facet of the capacities of some of these bash commands.
To view the full extent of parameters and uses of commands, use the man <command> (manual) command to look up documentation.
You can use the man command on virtually every command to receive full documentation on its usage.
The man -k <keyword> parameter can be used to look up keywords instead.
On many systems (Ubuntu included) typing man <command> for builtin types will return no manual page, but will return one for executables.
Experiment with which commands we've covered today have a manual page associated with them and which do not; what appears to be common with those that are builtins?
Whew! What a whirlwind tour of file systems and some rudimentary bash commands! Next week, we'll look at ways to start manipulating files using bash.