Disk Commands
Though we have the logical file system structure in our conceptualized back-pock, we should start to consider where the file system resides in hardware, and how different devices are integrated to give the user a seemless experience.
First, per usual, some definitions:
File storage is device-specific where devices / volumes are merely non-volatile storage media like hard and flash drives.
On Windows OS's, what typically identify the different storage devices?
Drive letters, like the C: drive.
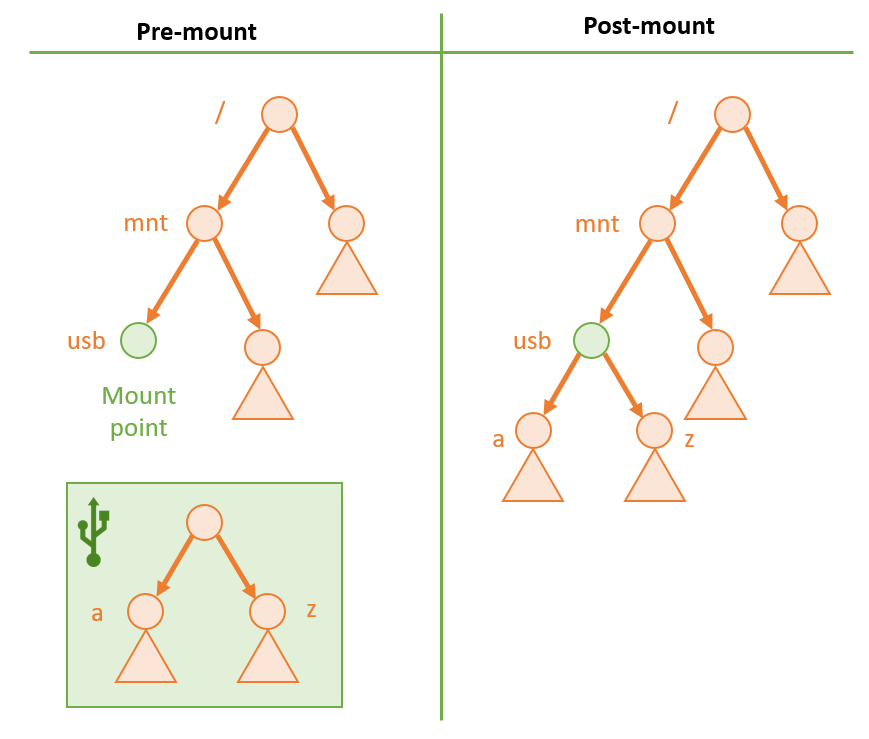
In Unix systems, devices must instead be integrated into the singular directory structure through a process called mounting.
Mounting a device in Unix systems is done by finding an empty directory in the FS at which to "affix" another volume's "subtree."
By convention, most Unix variants reserve the /mnt directory as a base directory for any mounted volumes, though mounted devices are not
required to be placed here.
The position in the directory tree at which a volume is mounted is called its mount point.
Thus, a device can be mounted into the directory structure and detached (i.e., unmounted) without disrupting other parts of the FS.
So how do we accomplish this in the terminal?
The df command (with -h "human readable" parameters) displays both free disk space and mount points for all mounted storage
devices on the system.
The (somewhat more cryptic) lsblk ("list block devices") command can be used to list all devices on the system, including those that are
yet to be mounted. Typical locations for mountable devices are in the /dev and /media directories.
Once you've selected a storage device to mount / unmount, use the commands:
The mount <device> <mountPoint> command will mount a device to the specified mount point.
The umount <mountPoint> command will unmount the device at the specified mount point.
Once a volume is mounted, its contents (proper permissions provided) can be accessed like any other in the directory structure.
Network File Commands
Just as disk commands examined how we can use local, physical volumes to access files on other FS's, so too might we be interested in resources that are stored on a network or on the web.
The scp <source> <destination> ("secure copy") works similarly to cp, except that the source being copied can be on a network location.
Typically, on-network secure copies require some user authentication, which are provided alongside the path of the remote file.
The syntax to copy a file from a remote network source to a local destination might look like: scp user@my.lmu.edu:/remote/path/test.txt /local/path/test.txt
The sftp ("secure file transfer protocol") works similarly, providing an interactive shell for the transfer of files.
If there are resources on the web that you would like to download, we've got commands for those as well!
The curl <url> ("check url") command can be used to fetch a document from the given url and display its contents in the terminal.
Note: if your system does not currently have curl installed, you can use the apt ("Advanced Packaging Tool") command to fetch it
from the list of accepted Ubuntu CLI executable packages, and a wide variety of other command line applications.
The wget <url> ("web get") command can be used to dowload a file from the provided url.
Later, we'll look at an example that has you fetching a web document!
Aliases
If you came here looking for Jennifer Garner, I hate to disappoint.
What you'll find might be even cooler!
By now, we've seen enough commands to note that there might be some common operations that you would like to perform repeatedly -- what a pain it would have to be to repeat them!
Just as we like to keep our code DRY, why not our bash interaction?
A bash alias is a user-defined mapping between a custom-command and some other commands.
It's a CLI shortcut!
The alias <aliasName>='<commands>' command sets the given command to its given replacement.
There are a variety of reasons aliases can be desirable:
Setting WD to common directories:
alias cdoc='cd ~/Documents'Replacing common commands with parameterized versions:
alias rm='rm -i'(interactive removal so that you never accidentally delete something important)Storing complex combinations of commands: ...
...hey, wait a second... we don't know how to do combinations of commands just yet! We'll look at that in a second.
Before that, let's try to set an alias and see what happens when we exit the terminal...
Set an alias, use it, close the terminal, and then try it again in a new terminal.
What happened to our alias?!
Bash sessions are begun and ended on a per-terminal basis, where a session is the user's interaction with the shell that is book-ended by login and logout scripts.
Bash login / logout scripts are files comprised of bash commands meant to prepare the bash environment for the user, including any environment variables and aliases to set.
You can look at bash login / logout scripts later, but for now, let's look at the one that's appropriate for setting aliases.
The ~/.bashrc is a shell script that is run whenever bash is started interactively, and contains environment and commands meant to prepare
the bash session.
Filenames that begin with a period / dot are called dotfiles, and are treated as hidden. They can be seen using the ls -a
parameter.
Tangent aside... since .bashrc is run every time a new interactive bash session is started, all we have to do is add our alias command to the end!
Add an alias command to the end of the .bashrc script, save it, and then try to use your alias.
What gives?! I thought we did everything we needed!
Why didn't our alias work after adding the command to the .bashrc script?
Because it's a startup script! We would either need to restart the terminal, or run it again...
To run a bash script manually, we can use the source <script> command.
Try using your alias after re-running the .bashrc script.
And there you have it! An alias that will persist between bash sessions.
I/O Redirection
Let's start with a little review:
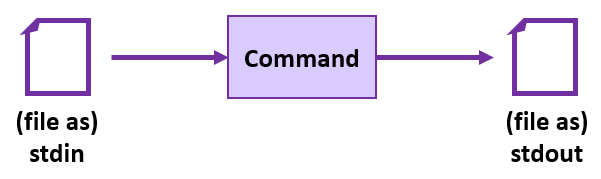
When we type in an interactive shell environment like bash (or your old school Java programs! remember Scanners?), through what mechanism is the keyboard programmatically attached to the program?
The standard input stream (stdin).
The standard streams are the "default" input / output channels connecting an application's user input and its output.
In the olden days, stdin was always the keyboard, and stdout was the monitor.
However, once we established that where our applications receive and deposit data could be redirected, the notion of redirectable "data" streams gained purchase.
Apropos, when we launch a terminal, stdin receives character inputs from the user's keyboard, and stdout returns each
command's feedback to the terminal.
Pictorially, this is a simple pipeline:

...but is there anything that says we can't change where this data comes from or goes to? Of course not!
I/O Redirection is the process of changing either or both of a program's input source or output destination.
Why bother redirecting input streams? To improve productivity of course!
Being able to nimbly redirect input and output can yield some impressive time-saving mechanics. Let's start with the how then unravel the why!
To redirect the input stream, we use the < operator, and to redirect the output stream, we use >.
So what kinds of things can we redirect streams to / from? Let's start with one of the most obvious: files!
Pictorially, of course, this looks like:
Redirecting stdout
Try to redirect the output of a few known commands to some text file.
Warning: redirecting output to a file will overwrite an existing file with the same name! Use at your own peril.
ls -i > inodes.txtcat EmacsSucks.txt > YepEmacsStillSucks.txtecho "quick file" > quick.txt
Redirecting stdin
Some commands we've already learned have an implied redirect of stdin.
The cat command, for example, expects a file whose contents to display, but is equivalent to redirecting a file as stdin to cat
More practically, if we have commands stored in some file, we can even execute them by redirecting the input to... you guessed it... the bash command!
Store some commands in a file called cmds.txt then: bash < cmds.txt.
Naturally, the next question we should ask is, "Can we, therefore, route data from between commands?" Of course!
Pipes
Sometimes, we don't want to go through all of the effort of redirecting a command's output to a file, which we then want to use as input to another command!
There's got to be a more streamlined solution, yes?
Pipes chain commands together, using the output of an earlier command in the pipeline as an input to its successor.
We use the | character to pipe commands such that in cmd1 | cmd2, the output of cmd1 will be the input of cmd2.
Once more, pictorially:

We haven't learned a whole lot of useful commands for pipe yet, but just so we can have one example on the docket:
The wc ("word count") command provides the number of lines, words, and characters presented to it via stdin.
Normally, we'd have to direct wc to a file containing some lines of text to examine, but with the magic of pipes, we can do some chains like:
echo "Hey here is a sentence out of nowhere!" | wc
This is, of course, not a particularly compelling example of pipes. We need some more sophisticated mechanics to see where and how it shines.
More on that next time!