More on Files
Not to be confused with Moron Files, the alt-title of America's Funniest Home Videos.
Last class, we looked a the file system structure of most OS's from a high-level standpoint, and saw how they could be hierarchically organized and considered in graph structure.
We call this viewpoint the logical file system model.
The logical file system manages file metadata information, including the FS structure, but does not include the actual data or contents of files.
This is the abstraction of the file system that humans and most application programs interface with; it is intuitive and follows a hierarchical directory structure.
We also saw a graphical visualization of the logical FS, but now we'll take one step deeper into the implementation, which we'll examine in greater depth later in the course.
Intro to File Control Blocks (FCB)
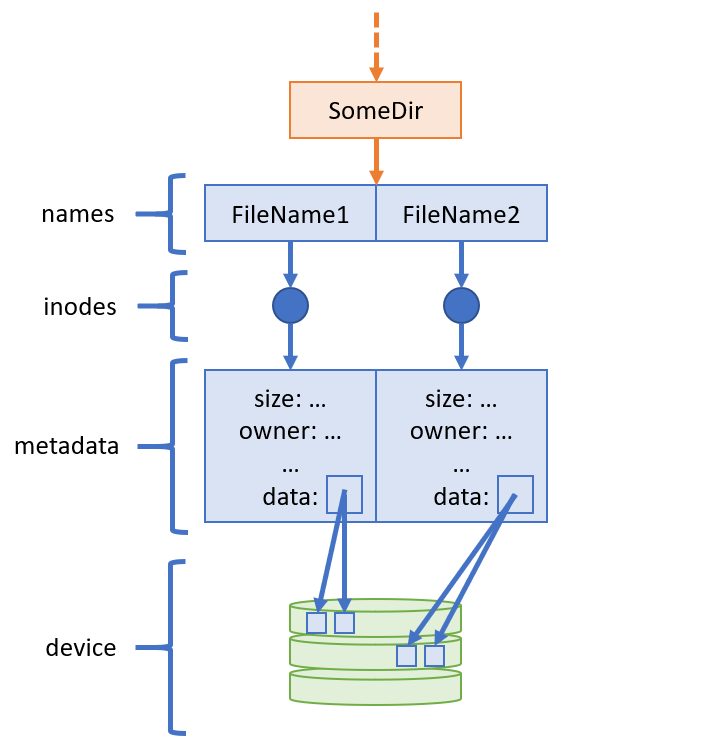
A file control block (FCB) contains metadata about a file and its unique identification on the storage volume.
In Unix systems, the FCB is called an inode (index node), which associates a unique inded number to every file on the volume, as well as the file metadata.
List some important metadata that you think should be contained within an inode.
An inode contains the following fundamental information about a file:
Permissions: system and user flags that protect the file from unauthorized tampering (looked at later in Security)
Timestamps: includes when the inode was last modified (
ctime), when the file itself was modified (mtime), and when the file was last accessed (atime).Owner(s): the userID and groupID of the file's owner for security purposes.
Location: where the file resides in the logical directory structure, including the volume / device name
Size: how many bytes the file occupies on the volume.
Data blocks: pointers to where the file's contents exist on the device.
Other data: discussed later once appropriate context has been established ;)
We'll examine many of these individual characteristics later in greater detail.
Here's a pictorial representation of how we can envision inodes.
More on Links
We saw links when we began our discussion of the graphical file structure in the class prior, but we should take a deeper look at links and their different types, and specifically, how they relate to inodes.
Every file is managed by exactly one inode, but multiple names can refer to that single inode.
Whenever a file is created, and an inode is associated with it, the file name is actually a hard link to the inode.
A hard link is simply a stored index corresponding to an inode. All directory entries are hard links.
A soft / symbolic link is simply a file that stores the location of a hard link file, which are then resolved if the referenced hard link exists.
Pictorially, this looks like:
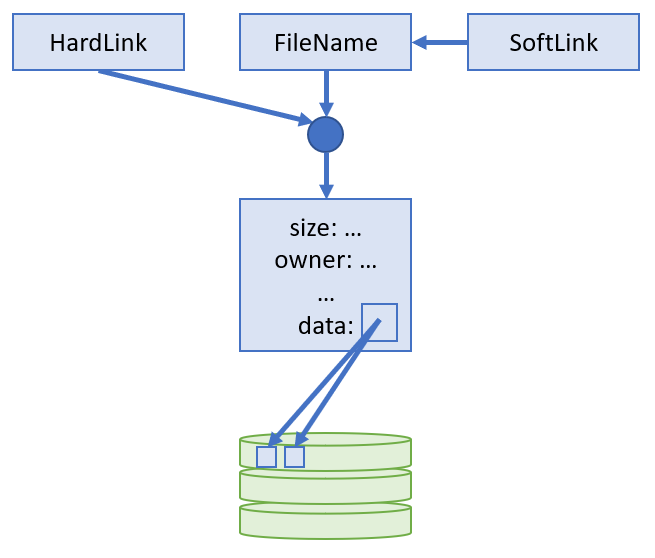
Rule of thumb: soft links refer to a path while hard links refer to an inode (by number).
This begs some important questions about the consequences of making a hard vs. a soft link.
If a file's contents are changed (like adding text to a .txt), will these changes be represented in a resolved soft-link? What about a resolved hard-link?
Both soft and hard links will refer to the modified inode, and so the changes will be represented in each.
If a file's name is changed (like renaming or moving the original hard-link), will any existing soft-links follow the move? Will other hard-links follow the move?
A soft-link referring to a hard-link that is changed will be broken, but any other hard-links to the same inode will be safe.
Looking at our visualization of hard and soft-links, when can we safely declare that the memory associated with an inode can be freed?
Whenever the number of hard-links referring to it is 0.
For this reason, inodes also track a counter of the number of hard links referring to it, but do not store the hard links themselves.
A reasonable question to ask is: why are there different types of links, and what are the advantages / disadvantages of each?
Hard links are built into the logical file system directory structure (discussed later) whereas soft links are files that take up storage and require some memory and computational overhead to resolve.
In general, to list a few of the times we would prefer one over the other:
Trait |
Hard Links |
Soft Links |
|---|---|---|
Change of Target |
Will still point to target inode, even if moved. |
Will break if its target hard link is moved. |
Links to Directories |
Cannot refer to directories. |
Can. |
Intra- and Inter-FS |
Cannot point to files in other devices / FS's. |
Can. |
The fact that hard links cannot be made to directories implies that the Unix FS itself is a tree structure, though the integration of soft links allows for certain graphical interpretations (though recall that soft links are ignored in a number of system operations like search).
Later, we'll examine the commands for creating soft and hard links, though the links created by the GUI "Make link" option are soft links.
Unix File System Commands
In the last lecture, we took a look at some common FS commands to navigate an existing Unix FS, but a reasonable question remains:
How do the files and directories get there to begin with? In other words, what are the commands to manipulate a Unix FS?
File Manipulation Commands
In this first section, we'll examine the commands necessary for creating, manipulating, and deleting files and directories.
File Creation
The touch <file> command can be used to create a new file in the system, or modify existing meta-data on a file.
A variety of terminal text editors exist, though the two most popular are vim and emacs.
There have been religious wars throughout history with less fanatical defense than the entrenched camps of vim vs. emacs supporters, but you can try out each and see which you prefer!
Generally speaking, emacs is a more powerful, but cumbersome, editor whereas vim is a simple, portable one.
Either can be used to quickly create or edit documents, and are typical companions of bash's working directory.
Once we have some files (created through a number of different means, touch, vim, or emacs included), we may want to copy, move, or rename them.
The cp <source> <destination> (copy) command copies the given file to the given directory.
This is fairly straightforward for files themselves, but we can imagine some edge cases with directories.
What are some directory edge cases we should consider with a copy command?
We should consider directories that are not empty, because we need to know what to do with their contents as well!
As such, we have another command parameter to the rescue, which crops up in several commands:
The recursive parameter -r applies a command to all sub-files and directories as well.
File Paging
It would be rather wasteful if we had to open a text editor every time we wanted to see the contents of a file.
Mercifully, there are a variety of commands useful for seeing the contents of a file.
The cat <filename> command displays the file's contents in the terminal, but is not great for large bodies of text.
Indeed, cat will simply dump all of the file's contents to the screen, regardless of whether or not there are multiple "pages" to read through.
This can make searching for particular lines quite difficult. Of course, other tools were invented for this case:
The more <filename> command is a pager that displays the contents of a file page-by-page, allowing readers to
simulate the act of scrolling in the terminal.
The less <filename> command is an enhanced version of more (less is more lulz).
Directory Manipulation
The mkdir command creates a new directory.
The rmdir command deletes a directory.
To create nested directories, use the mkdir -p <nestedPath> parameter.
Note, intuitively, that it would be dangerous to use rmdir on a directory with contents; as such, this command only work for empty directories.
As such, another commands suits this purpose, but should be used carefully due to its awesome destructive power:
The rm <target> command will delete a target file; use the rm -r parameter to remove all sub-directories of the target
as well (use with caution!)
Thus does the above contribute to the memesphere's rm -r /*, indicating that an entire volume should be wiped (doesn't really work, mercifully).
Moving and Renaming
The mv <source> <destination> removes the file or directory at the given location and relocates it to the destination.
This is also how to rename files in Unix systems, provided the path in the source and destination are the same.
Earlier in the class, we looked at the 6 basic file operations that should be supported by an OS, and the "rename" complex operation was shown to be implemented with some of the primitive operations.
This procedure generated some controversy; why go through the trouble of copying a file to rename it if we can just change its name?
Indeed! While we *could* implement the complex rename behavior with the primitive file actions we described, what's a simpler way of changing a file's name?
Simply change the name associated with the hard-link that points to the inode of the file!
Although most modern systems support this renaming behavior, it was not part of the theoretical *minimums* (i.e., primitive) operations associated with files that we examined last lecture.
Link Manipulation
Recall earlier that the purpose of links in pursuit of shared files and convenient shortcuts, but now we are aware that there are different types of links.
Let's look at how we can establish each using the ln command.
The ln <target> <name> creates a hard link to the target known by the provided name.
The ln -s <target> <name> (with -s parameter) creates a soft link to the target known by the provided name.
The ls -i parameter can be used to see information about each file's inode in the current working directory, including which links
refer to which inodes.
Rather than have me show you how to use these, let's put your skills to the test!
Classwork 1
Time for your first classwork! Head on over to the CW page for instructions:
Classwork 1