Questions from Last Time
[Q1] How to prevent black-hatted tricksters from aliasing important Bash commands, and then aliasing unalias so you can't unbind them?
It turns out prepending a backslash to a command will use its un-aliased version, so e.g., \unalias will execute the unalias command even if it is shadowed.
[Q2] How to use sed on nested sub-directories.
This question requires a bit of explanation, starting with: why doesn't sed support the recursive -r parameter?
Well, because then it opens the question: should the replacement apply to files and folders alike, or just files?
As such, the work-around is to use a search operation to execute sed on all resulting files of the search. This resolves the issue of renaming crucial parts of directories on accident.
The find <params> <rootOfSearch> <attributes> command can be used to find files and directories rooted along some path. It's components are:
rootOfSearchis a path specifying whose subdirectories to search.attributesare specifications of what file attributes to search for, like-name "Emacs*.txt"will search for every text file with Emacs in the name, or-type f, which returns only files (not directories) (see man for more).
In addition to the above behavior, which will (by default) ignore symbolic links during the search, specifying the -L parameter will instruct the command to also follow symbolic links.
Plainly, you can imagine that adding the -L can be dangerous if symbolic links introduce loops in the FS structure, but find is smart enough to detect those.
Try creating a link to your Documents folder inside of your Documents folder and see what happens when find is used with the -L parameter.
Now, back to the original discussion: how to use sed on nested sub-directories?
The find command possesses a particular attribute called -exec cmd that will execute the given command on each of the found files wherever a parameter substitution
{} special symbol is found, and then terminated by \;.
Try performing a replace operation on all files and subdirectory files of your Documents folder (having made some files in subdirectories that will be affected):
find ~/Documents/ -name "test.txt" -type f -exec sed -i "s/test/hi/g" {} \;
Whew! What a beastly looking command! Do you feel like a 1337 hacker yet?
[Q3] The {} special symbol is neat when appropriate, but can we substitute the results of arbitrary commands as arguments to other commands that are not used to direct the input stream?
As it turns out, yes!
As we saw briefly last lecture, grouping commands using parentheses (cmd1 ; cmd2) actually starts what's called a subshell -- bash session started within our bash session!
We'll discuss this later when we talk about processes that spawn other processes.
Importantly, any text that is written to stdout during a subshell's operations will be returned to the host shell's stdout. However, if we wish to use the results of a command as an argument to another, we employ one other tool:
The bash special symbol $ is used to evaluate environment variables (check them out for your homework!).
Try setting an environment variable: a=5 then evaluating it: echo "a is $a"
When used before a subshell invocation, the $ symbol will cause anything written to stdout in that subshell will instead be used in place of where that grouping occurred.
So, we can use the subshell to fetch the argument we want for a separate command in the host shell!
For example, we can search subdirectories for the contents of a particular file:grep -r "$(cat ~/Documents/test.txt)" ./*
OS Structure: Memory
With that review in place, let's start at the beginning with OS's with some important questions:
We know an OS is just a program... so where does it live and how does it get loaded when the computer starts?
We also know that the OS is the program that runs all other programs, and is the bridge between the hardware and software... so how does it accomplish this role as a bridge?
We'll start by answering question #1, but before we do, we need a somewhat deeper understanding of a computer's storage structure.
Storage Structure
Let's recall our conceptual overview of the hardware in the Von Neumann Architecture (VNA):
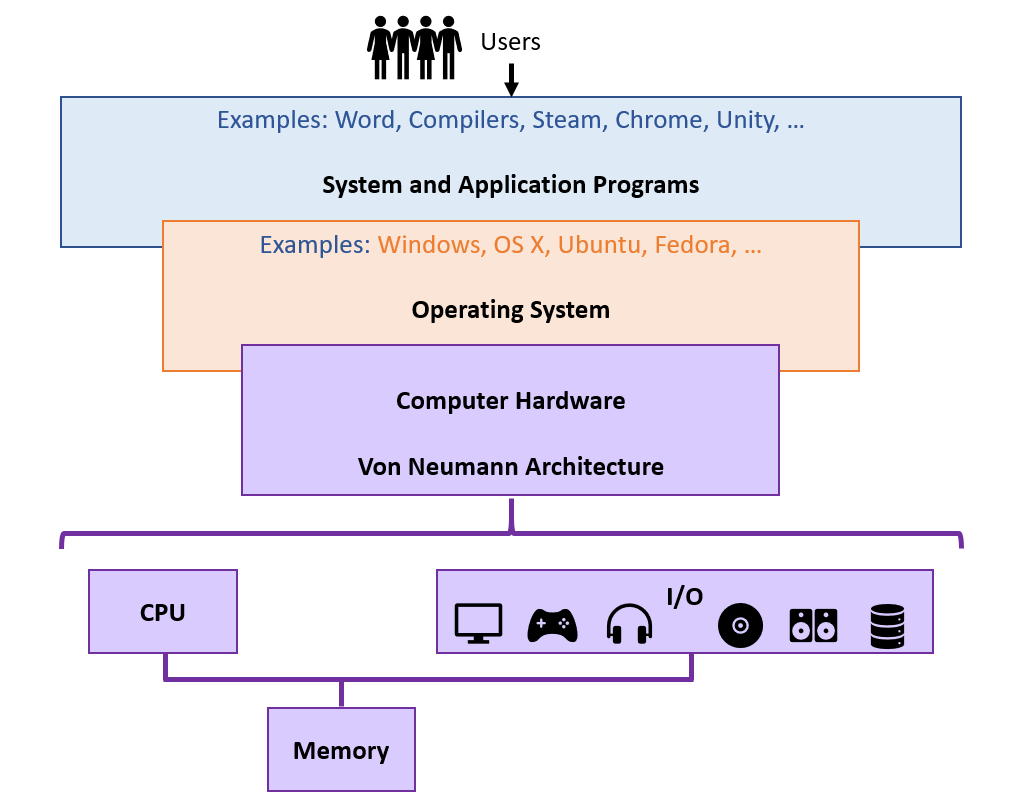
At some level of abstraction, the VNA's major tasks are to simply: load, modify, and store data.
Typically, this is depicted through in the VNA "Main Memory," as implemented in RAM.
This memory must be pretty important in order to be labelled "Main."
In the context of a computer's operations, what is special about RAM?
It is where instructions of any active processes are loaded from during the CPU's Fetch, Decode, Execute cycle, as well as data that is relevant for the execution of those processes.
In the ideal world, we would have infinite amounts of RAM, and it could serve as our single repository for all data.
Indeed, (for recent Theory students), what would a system with infinite RAM look a lot like?
A Turing Machine!
That said, whereas in Theory we had the benefit of thinking about memory... well... theoretically, there are some realistic concerns that we have to address in practice.
What would be some drawbacks of implementing an all-RAM storage system?
(1) Too small to hold all data and programs of interest, and (2) volatile and therefore impermanent.
Solution: move volatile data into and out of non-volatile storage as quickly and efficiently as possible.
Indeed, programs themselves are first saved on some permanent storage volume before they are run as an active process.
Once a program is copied into RAM from the disk and is being run on the CPU, the processor must also temporarily copy information from main memory to be able to process it!
As such, we see that there is actually storage in *all 3* main components of the Von Neumann architecture.
Main memory serves as a bridge between disk storage and the processor's temporary storage.
Plainly, then, each of these disparate storage locations in the architecture have their own purposes, pros, and cons.
This establishes a storage hierarchy in which memory that is closest to the CPU will be the most quickly accessed, but also has the lowest capacity and highest volatility.
The rule of thumb: the fastest memory is the costliest, and is located closest to the CPU, but the slower memory is less expensive and located farther.
Let's take a look at the hierarchy now!
Memory Hierarchy
The memory hierarchy is divided into four major tiers, ranked in "closeness" to the processor:
Hardware Memory is implemented at the mechanical level aboard the CPU chip and includes the processor registers and cache. However, since this memory is handled outside of the OS's influence, we will not focus on this type of memory much in this course.
Primary Storage is implemented as RAM: the bridge between hardware memory and extended into non-volatility into secondary storage.
Secondary Storage includes magnetic and electrical disks (your "hard drives") which can be thought of as permanent extensions of RAM.
Tertiary Storage includes optical disks and magnetic tapes, and pretty much anything else that isn't the above.
A picture is, of course, worth a thousand words (I'd know, I've written about that many already).

Caching
Reasonably, you might ask: if the hardware memory is not the OS's business, whose is it and what kind of speed differences are we talking about?
Here's a layout of the 4 most commonly interacting classes of memory:
Level |
Name |
Typical Size |
Access time (ns) |
Managed by |
|---|---|---|---|---|
1 |
Registers |
< 1 KB |
0.25 - 0.5 |
Compiler |
2 |
Cache |
< 16 MB |
0.5 - 25 |
Hardware |
3 |
Main Memory |
< 64 GB |
80 - 250 |
OS |
4 |
Secondary Storage |
> 100 GB |
5,000,000 |
OS |
Given these differences in access time between the different storage media, in what tier would we want commonly used data to be kept?
Well certainly not in secondary storage! Typically, the best optimization happens at the level of the cache.
Caching is the process of copying information from a lower memory tier into a higher one under the assumption that it will be needed again in the near future.
If we keep all of our most frequently used data close to the CPU, we'll waste less time fetching it from slower tiers!
What are some foreseeable challenges to caching?
Biggest: (1) Cache size is limited, so only some data can be stored for reuse at a time, and (2) multiple processor cores = multiple caches, must make sure there is coherency with resources copied into multiple caches.
Reading and writing data can be considered a sort of "climbing up and down" the memory hierarchy.
Suppose we have some integer in a file on the hard disk, call it A. In order to be processed, copies of A will exist in each layer: $$A_{disk} \rightarrow A_{RAM} \rightarrow A_{cache} \rightarrow A_{register}$$
The benefit: if \(A\) is required a second time after it has been copied into the cache, we do not have to copy it all the way from the disk again.
The drawback: multiple processors will each have their own \(A_{cache}\), and so the process of cache coherency must ensure that these separately cached versions of \(A\) are always kept in sync.
That said, cache coherency is typically handled at the hardware level and so we rarely have to worry about it programmatically.
So now that we've looked at the directionality of Main Memory to Hardware Memory, let's consider the other direction.
I/O Structure
Recall that every storage medium below Main Memory is considered an I/O (Input / Output) device, akin to a mouse, monitor, etc.
All I/O Devices have corresponding device controllers, which communicate with CPU and RAM using a device driver.
Device drivers are specialized to handle whatever data is being sent from each device and create a uniform data stream to be interpreted by the system.
Reasonably, you might ask how devices "get the attention" of the OS to transmit whatever data they have to share.
I/O interactions are driven by interrupts, which stop the CPU from what it's doing to immediately transfer execution to some known position in memory.
Since each interrupt will come from a particular device with its associated driver, these known positions in memory can be quickly addressed.
The table of pointers to device-specific interrupt routines are stored in the interrupt vector.
Usually, these are stored in the low memory addresses (first ~100 addresses or so).
Once the interrupt routines have been located, the interrupt process follows several basic steps:
The driver interface is invoked.
The driver sends instructions (and possibly data) to the device controller's registers and local buffer.
The device controller performs the necessary transfer of data to/from the local buffer.
Once completed, the device controller sends an interrupt to the device driver, returning control to OS with the new data.
Depicting these interrupts:
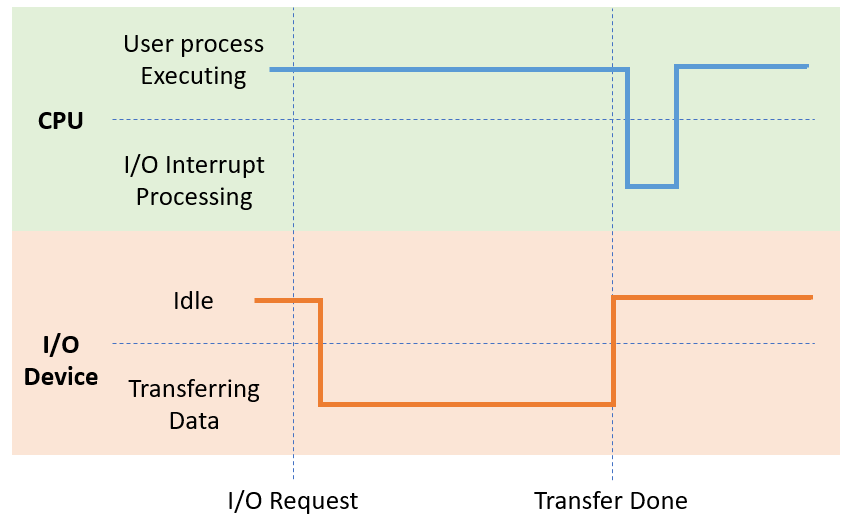
Note the slight delays after parts of the interrupt events: these are to account for the delay caused by caching, lookups in the interrupt vector, and device handlers.
Devices that we might otherwise expect to be lagged by this process demonstrate the awesome speed of modern computers: think about your mouse movements, how quickly their input is represented on the screen, and that the above is happening thousands of times in the span of seconds!
Considering that some I/O devices (like disks!) are simply used to populate data in the higher memory tiers, why might it be wasteful to interrupt the processor?
Because the CPU can be doing something else rather than worrying about a transfer of data!
For this purpose, modern systems will equip some devices with Direct Memory Access (DMA), by which device controllers may read/write from/to main memory directly without interrupting the CPU.
We'll look more deeply at memory management and mass-storage management in the later 3rd of this course, but now let's return to our original question:
Where does the OS "live" and how does it first start to run?
OS Structure: Booting
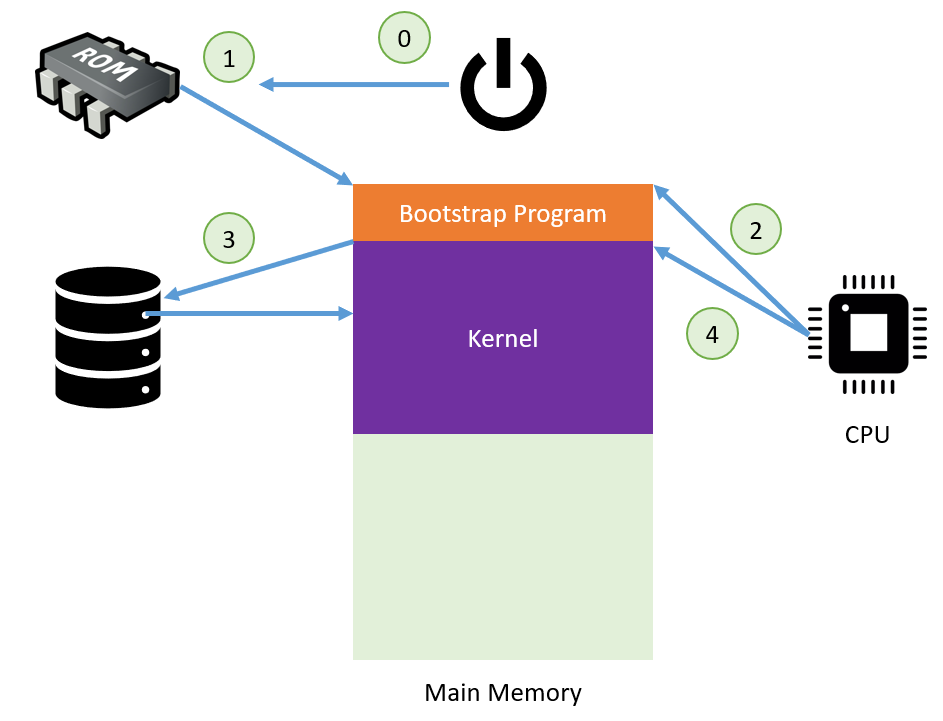
When a computer is freshly turned on, it requires a program to run!
Naturally, we would like that program to be an OS, but the mechanics of this startup process require some investigation.
The process of loading the OS kernel is referred to as booting.
The first step of this process is accomplished by a simple program that simply gets the ball rolling.
The simple program that loads the OS kernel and initializes all other system settings (registers, device controllers, etc.) is called the bootstrap program.
The bootstrap program is nothing fancy, and simply passes the torch for the booting process through severa; simple steps:
When the computer is turned on, the bootstrap program is loaded into Main Memory and then locates the OS kernel via the boot block, a storage location containing the code to load the OS kernel.
Code executed from the boot block performs diagnostics and then loads the kernel into Main Memory as well.
The CPU executes the OS kernel code, which then assumes control of the system, waiting for any events to dictate its next operations.
Knowing what we now know about the memory hierarchy, where do you think (most) OS kernels are stored?
Secondary storage, on disks that are said to have a boot partition to hold the kernel.
Knowing what we now know about the memory hierarchy, does the bootstrap program belong in any of its tiers? Why or why not, and if not, where should it be stored?
Anything higher than secondary storage is out because of volatility, and secondary storage is out as well because we don't want to expose something as important as the bootstrapper to viruses.
For these reasons, the bootstrap program is typically stored in some form of read-only memory (ROM), usually located in chips atop the motherboard.
All forms of ROM are also known as firmware because, although a software resource in nature, they are not modifiable, and so resemble hardware components as well.
Once more, to depict things visually: