OS Structure: Responsibilities
Last time, we looked at hardware and memory organization with relation to the operating system, but now it's time to consider how the OS itself should be structured once it's been loaded by the bootstrapper.
We'll begin this endeavor by abstracting the OS' primary responsibilities and then seeing how we can best accomplish these.
At the highest level of abstraction, an OS must be able to support 2 related functions:
Multiprogramming [Shared Memory]: maintaining and switching between more than one job or process in memory, including the maximization of efficiency for whenever a process demands some I/O operation (which, if we recall from last week, can take a long time).
Multitasking [Shared Processing]: the ability to switch between jobs quickly enough that multiple users percieve an interactive experience (relies on humans being significantly slower than most computer operations).
In brief: since we have many programs demanding shared resources on a system, the OS must be able to accommodate each in such a way that the sharing is imperceptible to the user.
It is from these two basic demands that we then divy the specific roles of the OS:
Process Managers decide which jobs or processes in the job pool should be stored in main memory (job scheduling) and which should currently employ the resources of the CPU (CPU scheduling).
Memory Managers coordinate what is stored in main memory; a challenge because there is finite actual memory, and so the memory manager implements a virtual memory scheme, which pretends that there is infinite memory and then swaps data in and out of the actual RAM to simulate this.
File System Managers handle the requirement to maintain data that cannot be stored in volatile RAM.
I/O Managers support the above.
Since all of these individual tasks are expected of the Kernel, a reasonable question arrives:
How should the Kernel be structured to address these needs?
Operating Modes
Before we start structuring our OS's, we need to take a peek at just how the OS treats its own operations and those of the user.
When we were discussing device I/O, how did devices inform the OS that they had data for it from some I/O Request?
Through an interrupt that was handled by the device controllers and drivers.
Modern OS designs are called interrupt-driven since almost all activity is initiated by an interrupt.
As such, just as hardware can request the attention of the OS through an interrupt, it stands to reason that software should have a similar system in place.
Software interrupts also each have a corresponding handler / service routine deciding what should happen when the interrupt is received.
The Interrupt Vector (as discussed last week) is an in-memory mapping that determines which interrupt is associated with which handler.
Just as the interrupt vector decided which device driver would handle which hardware I/O interrupts, so too will it decide which service routine is associated with a software interrupt.
Recall also that this is simply a pointer to some location in memory instructing the system what code to run in response to the particular interrupt.
There are 2 main types of software interrupts:
Exceptions are caused by processing errors (e.g., division by 0, illegal memory accesses, etc.)
System Calls are explicit, user-given requests to access operating system resources and functionality.
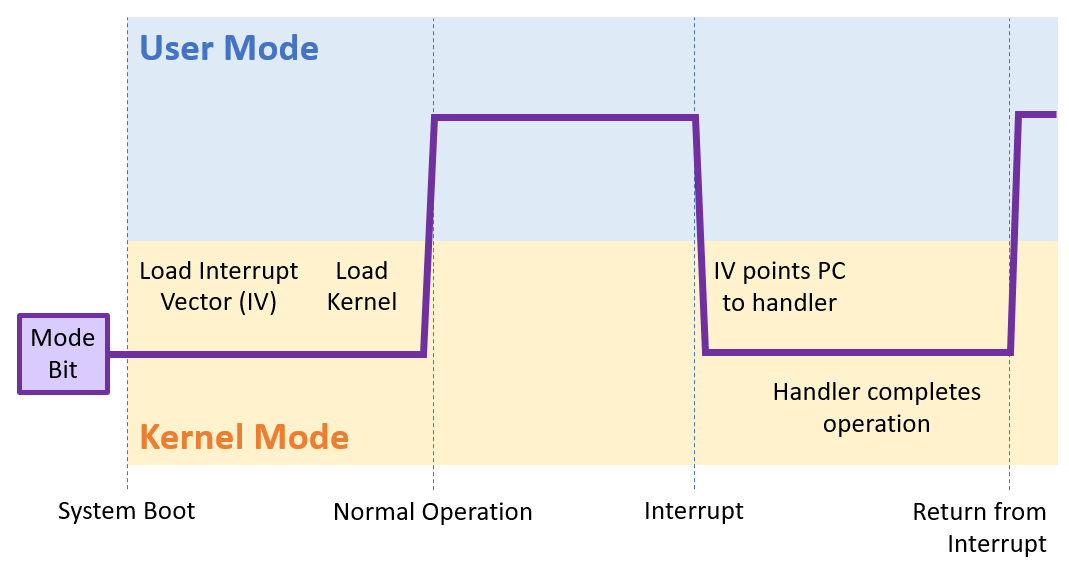
Since an interrupt can be made from application software, we see that at any time, an OS is executing instructions from either some user program or the kernel.
Since the kernel is operating in main memory, and a software interrupt is a request to the OS (which may request a modification to main memory itself), what are some dangers to interrupts that an OS will have to consider?
Primarily that instructions from a user program which modify memory may not tinker with (1) other user programs in memory, and especially (2) may not tinker with the kernel.
This serves as not only a security concern for black-hatted user applications seeking to corrupt other programs, but also to prevent faulty / buggy programs from unwittingly affecting the performance of others.
If the kernel is a program in memory, and user applications are programs in memory, how do we know which can legally manipulate memory and which cannot? Suggest some implementations.
The need to control for some instructions to only be conducted by the OS has led architectures to what is known as dual-mode operation.
Modern processors support dual-mode operation by which a hardware-bit signals that the currently executing code is either: user-defined code (user-mode) or OS code (kernel mode (AKA supervisor, system, or privileged mode))
How do we track what mode we're in?
As it turns out, modern processors have a hardware-level mode bit that determines which mode is currently active.
Knowing what we now know about dual-mode operation, we can see how the OS addresses some of its fundamental responsibilities:
Challenge 1: Using dual-mode operation, how could we ensure that the operating system is always the first in control of the computer and that other programs are not able to perform any malicious tasks pre-boot?
When the computer is powered on, the mode bit is started in kernel mode so that no malicious code can preempt boot.
As soon as the OS is fully booted, and the first user-program is executed, the OS will switch the mode bit back to user mode.
Certain instructions (like initiating I/O or saving data to protected memory) are called privileged instructions as they are only meant to be used by the OS alone.
Challenge 2: If a user program attempts to use a privileged instruction, how should the OS prevent it and what should happen?
The processor need simply check the mode bit; if it is not in kernel mode and a privileged instruction is encountered, then an exception is thrown.
Challenge 3: If a user program begins monopolizing processor time (e.g., infinite loops), but there are important tasks still required to be carried out by the kernel (e.g., switching to another process), how can we guarantee that the OS can always maintain control?
Have a timer interrupt that periodically triggers an interrupt and switches to kernel mode.
As such, having a timer interrupt serves as a periodic "check in" with the OS so that it can always carry out its duties, despite what malevolent state the user program has taken.
Of course, now, to close out this wall of text, we should depict the timeline of an interrupt:
OS Structure: Kernel Design
Given what we now know about dual-mode operation, a reasonable question presents itself for how we should structure the kernel's components:
Consider: of the OS' responsibilities outlined above, which should be a part of the kernel and which should be delegated to systems programs?
This question has been asked since the early days of MS-DOS (which answered it rather poorly, not planning for the growth that it would eventually experience).
As such, we'll look at some structures for the kernel components, including how some modern OS' are implemented.
Layered Kernels
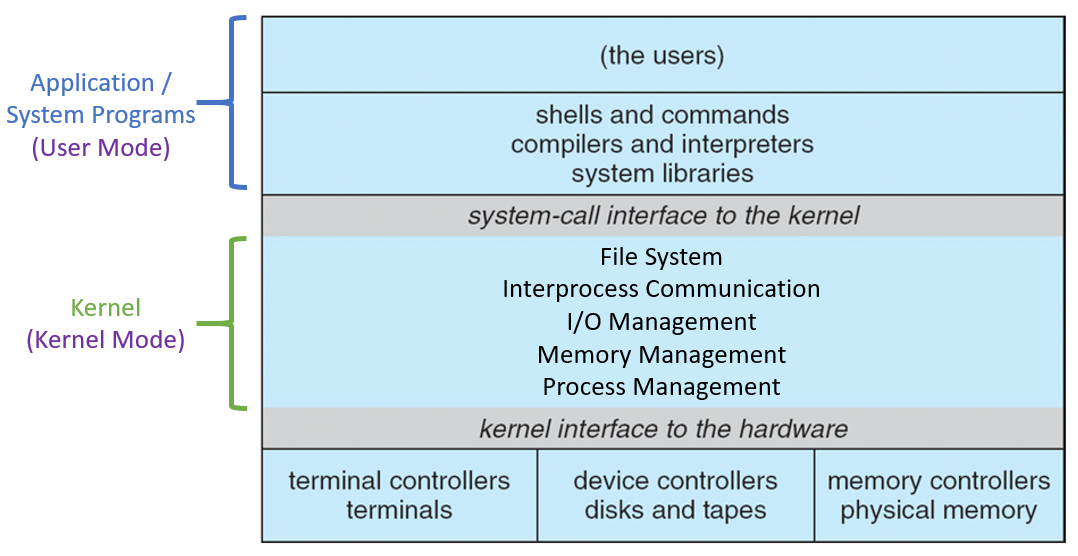
In the early versions of Linux, the primary design goals were simplicity and ease of debugging.
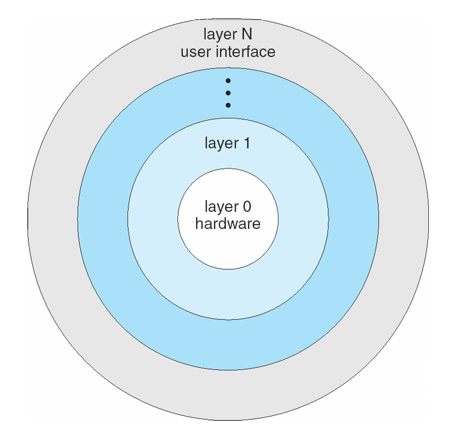
Their structure was intuitive: position the user interface at the highest level of abstraction, the hardware at the lowest, and then create a hierarchy of kernel components that would serve as layers.
The layered OS structure is structured such that each layer consists of specialized data structures and operations that can manipulate that layer's data, and are available only to that layer and layers above it in a hierarchy.
It's starting to seem like everything in OS's are becoming hierarchically organized!
To depict the levels of access, we might envision:
Moreover, in terms of how the actual kernel components appear in relation to the users and hardware, we have:
So was this a good design decision?
What are some benefits of the layered OS approach?
Once the layers are in place, easy to appropriately implement each layer using the tools of the one below it.
Easy to debug: can iteratively test an operation from the lowest layer up such that the first layer with a problem will likely contain the bug.
Clear "separation of concerns" between layers
What are some drawbacks of the layered OS approach?
Planning which layers should be built atop which others can be complicated, and difficult to resolve mutual dependency.
Not particularly efficient, because certain requests that begin at the user level will have to travel through each layer before reaching the hardware.
Indeed, because of these efficiency concerns, and the fact that, as OS's became more and more complex in the modern era, a different approach was proposed...
Microkernels
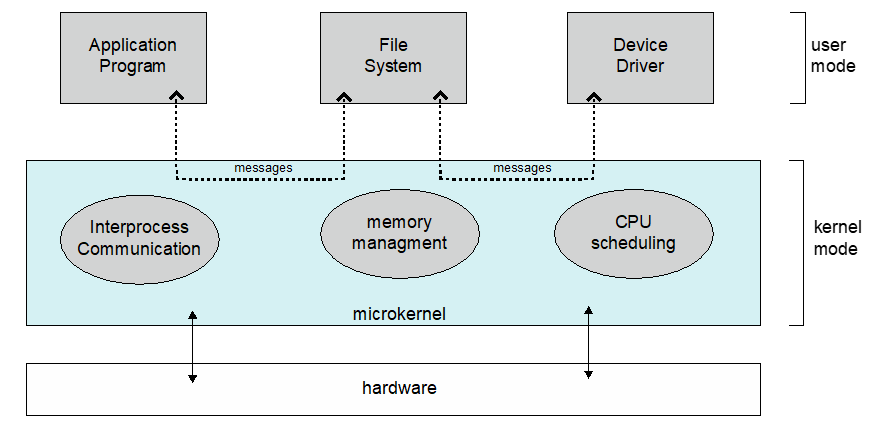
As the name suggests, the main allure to microkernels was to strip the kernel down to only its bare-minimum requirements, and delegate all other work to user and systems programs.
The Microkernel approach removes all nonessential components from the kernel, implements them as systems programs, and leaves only minimal process and memory management in the kernel.
Microkernels are used (in part) to compose the Mac OS X kernel, though it uses something of a hybrid approach that we will examine shortly.
To depict a Microkernel (from your book):
What are some benefits of the microkernel OS approach?
Small kernel means a smaller memory footprint
Easier to extend the OS: if a new component is needed, simply create an appropriate systems program while needing to make minimal modification to the kernel.
What are some drawbacks of the microkernel OS approach?
From a design standpoint, difficult to reach concensus what should remain in the kernel or ported to a systems program.
Efficiency penalties from needing to switch between user and kernel modes for many systems-level tasks.
As such, a "best of both worlds" approach has somewhat dominated the modern era of OS structure...
Modular / Hybrid Kernels
Modular / Hybrid Kernels are generally composed of microkernel "cores" that then dynamically loads (i.e., during runtime rather than merely at boot) any modular components that are required.
Each module resembels a layered system in that they have internal hierarchies, but any module can call any other module, and any can invoke the "microkernel" core.
As an example, the Solaris (an early Unix flavor developed by Sun) kernel is decomposed into modules looking like:
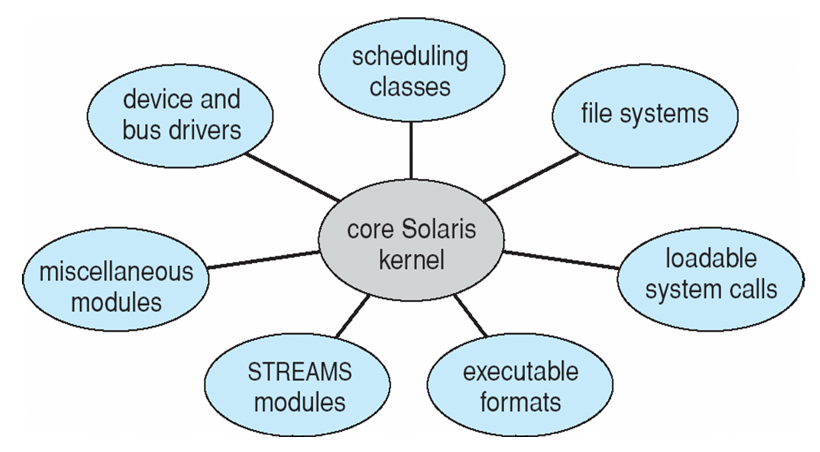
And there you have it! Some important OS structuring decisions in a nutshell.
Next time, we start to dive deeply into System Calls and how to use them ourselves!