Process Scheduling
As we hinted at last week, one of the most important roles of the OS in pursuit of multiprogramming and multitasking is deciding which processes are granted the resources of the computer at any given time.
As you might imagine, with a variety of different processes ready to execute at any given time, this responsibility can grow in complexity.
The OS addresses this responsibility by implementation of a process scheduler, which selects which process should be actively executed by the CPU at any given time.
We'll look at how a scheduler is implemented shortly, but first let's consider its fundamental challenge in the following scenario.
Suppose we have a process, \(P_0\) that is currently in the Run state (i.e., it's executing) and then the OS receives an interrupt that must be handled by some other process \(P_1\). What would make sense for the OS to do with \(P_0\) if the OS needs to now execute \(P_1\)?
Save its state to be resumed later!
What record-keeping mechanism does the OS maintain to keep track of a process' state? In other words, where should its state be saved?
In the Process Control Block (PCB)! This is stored in the kernel's stack.
This is one of the most fundamental operations of process scheduling because it involves swapping one process from the CPU to another while maintaining its state.
Formally, a context switch occurs when an interrupt saves the state of a running process, and restores the state of another.
Visually, a context switch looks like:
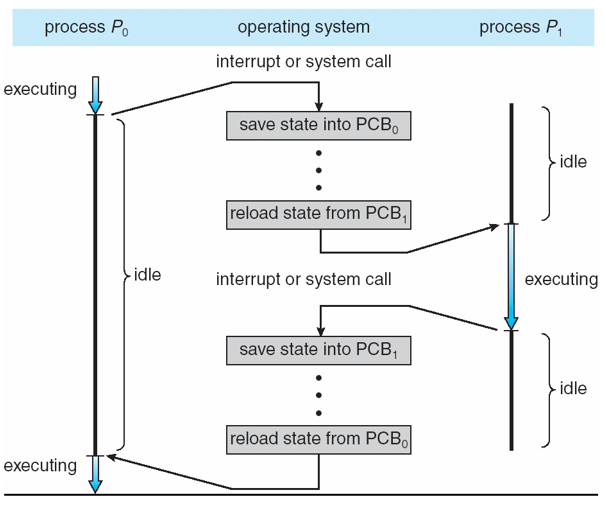
The above plainly illustrates what happens during a single context switch, but we haven't yet considered how to manage context switches between multiple processes.
ADT: We may, at any time, have a variety of processes in the ready state, but only a finite number of processors to assign them to. What data structure would make sense to store an ordering in which to execute processes that are ready?
A queue!
Implementation: Now, consider: There are likely to be many, frequent additions and removals of processes from the queue. How should we implement the queue and what would we be storing in it?
A linked list with a head and tail pointer to Process Control Blocks!
This is precisely how the process queues are implemented, but there are a variety of different process queues as well.
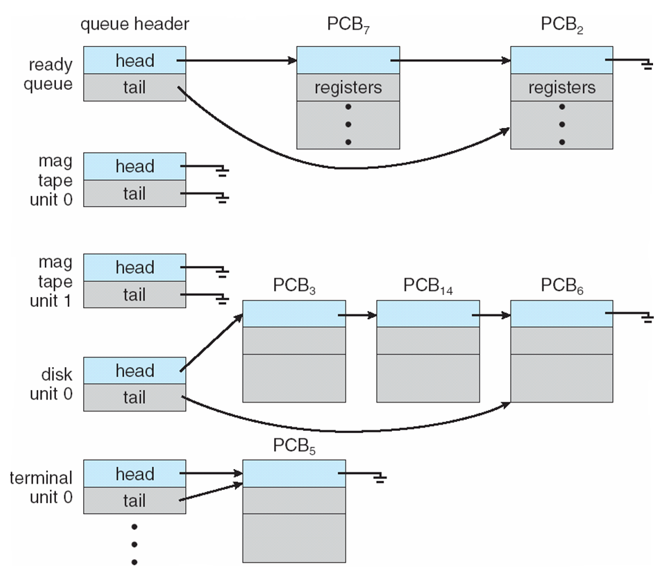
The three most significant process queues used in process scheduling are:
Job queue: consists of all non-terminated processes in the system.
Ready queue: consists of all processes in the ready state, pending execution.
Device queue: (one for each I/O device) consists of all processes waiting for an I/O request to complete.
What topic that we learned about in the first 1/3 of the course suggests the necessity of device queues and why?
The memory hierarchy, which asserts that I/O requests can take a very long time to complete, and therefore the processor can be doing
other things with other processes while a process is in the wait state.
Pictorially, these queues look like the following (again, shamelessly stolen from your text because I can't be bothered to draw some boxes):
Now that we've seen how scheduling happens, in the abstract, let's consider some more concrete operations that we can perform with processes.
Process Operations
Since we are all familiar with the fruits of multitasking and multiprogramming, it may come as a surprise that processes, too, are organized hierarchically.
A process may spawn a new subprocess via an OS' create-process system call, which varies from OS to OS. In Unix, creating a child process is to (and corresponds to the system call of the same name) fork a new process.
The creating process is called the parent, and the created process is the child, thus creating a tree of processes originating from the initial process.
To keep track of processes in the tree, each process is assigned a unique process identifier (pid).
...but enough of these definitions! Let's sink our teeth into some hands-on process practice... some proctice, if you will!
Process Inspection via Bash
Bash is a process like any other, and every command we give it is, unsurprisingly, a newly spawned child process as well.
Since Bash is our CLI window into the operatings of... well... the operating system, we can inspect the active processes
The ps (list processes) command provides information about each process' PCB that are in the job queue.
To see processes that are not simply user programs, we can append the -el flag, or if we're feeling really bold and want to see
kernel processes as well, -elf.
The output of ps -el can be overwhelming at first, but we can start to decode some of its most important information.
(as always, for a full account of the information ps gives you, consult the manpages).
Some of the ps columns, explained:
S: the state of the process, with codes like:A: Active
W: Swapped
I: Idle (waiting)
Several others (see manpages)
UID: the user ID of the process owner. A UID of 0 is always used to indicate the root user in Linux systems.PID: the unique identifier for the process.What do you think has the honor of PID 0? What purpose would it serve in the kernel?
PID 0 is typically the Scheduler, since all other processes have to be scheduled!
PPID: the PID of the parent process, i.e., the PID of the process that spawned this one.CMD: the name of the process, (including arguments if certain flags of ps are given)
Try sketching some parts of the process tree using the output of ps -el and inspecting each process' PID, and PPID.
Process Manipulation via Bash
Now for some fun manipulating processes!
Sometimes, we might want to have long-running processes run in the background of a particular shell (e.g., a Node.js server).
The for any command cmd, the Bash cmd & builtin operator (i.e., the &) forks a new subshell and
executes the given cmd in that subshell in the background.
Try the following steps to see this in action:
Try the following command:
ping www.google.com &Open another terminal and inspect the running processes
ps -el
What is interesting about the relationship of PID and PPID of the latest bash and ping cmds?
Now... how do we stop pinging Google?!
Welp... that's gonna go on for awhile, and our trusty CTRL+C doesn't seem to be stopping it!
Luckily, we can choose to target certain processes for termination via Bash as well.
The kill <pid> command (so violent!) force-terminates a process with the given PID.
So how do we find the PID of what we want to kill? Why ps -el of course! (other commands can be used to search for processes, pgrep, notably)
Try killing the rogue ping command we started above.
And there you have it! A brisk look at processes from the Bash perspective.
Next time, we'll look at them from (you guessed it) a programmatic perspective in C!