Threads
In our previous discussions about processes, we considered that processes represented a "passive" program becoming "active," having its instructions executed by the processor.
That said, we have yet to take a peek "under the hood" of the process under execution.
A single process may have multiple tasks that it must accomplish with the illusion (from the user's perspective) of concurrency.
Consider a video game that must "simultaneously" manage user input, compute game mechanics, display feedback to the player, etc. These are all tasks that the overall process is responsible for accomplishing.
What would be some drawbacks of delegating each of these tasks above to a separate subprocess?
There are two key drawbacks:
Copied memory may be wasteful
Cost of context switch between processes
It would be nice, therefore, if we could exploit the division of labor and parallelism afforded by forking subprocesses in a way that is more "lightweight" ...
Enter the notion of threads.
A thread is a basic unit of CPU utilization that represents a task within a process. A thread is composed of:
A thread ID (TID)
A program counter
A register set
A stack
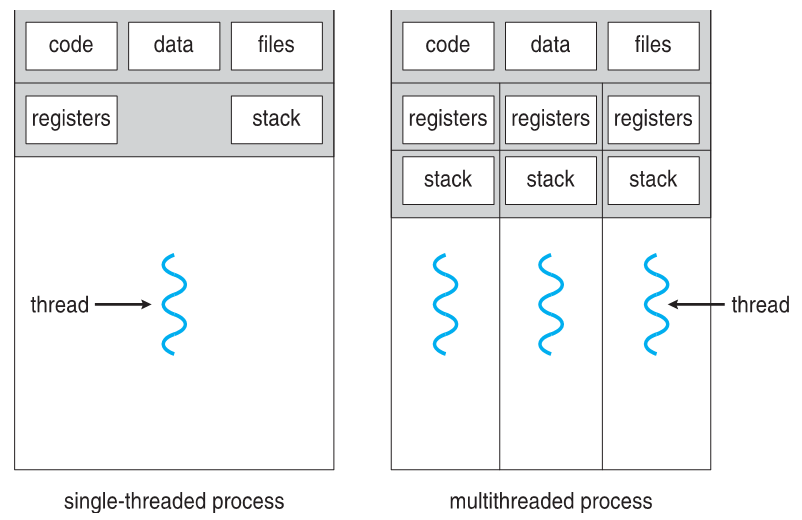
A traditional, or heavyweight, process is single-threaded (has a single thread of control).
These are the processes we've been dealing with up until now, and since each thread has its own stack, "the" stack we've been talking about all of our lives belongs to the single thread in our heavyweight process.
A multi-threaded process contains multiple threads of control, each with their own stack, but share the process' heap, text, and data sections.
In Linux systems, the stack of each thread can be allocated from the parent process' heap.
Pictorially (again, from your textbook):
Chief Benefits
So why use threads? There are four major benefits:
Responsiveness: parts of a program or process can be executing while others are waiting (e.g., web browser
T1:loading an image whileT2:capturing user input)Resource Sharing: processes must use IPC to share information; threads share the address space of a process and have access to data segment, heap, and any open files.
Economy: computationally more lightweight than subprocess creation: in Solaris, creating a process is roughly 30x slower than creating a thread, and context switches are roughly 5x slower for processes than threads.
Scalability: a single-threaded process can only use one processor no matter how many are available. Multi-threaded processes can exploit parallelism even more.

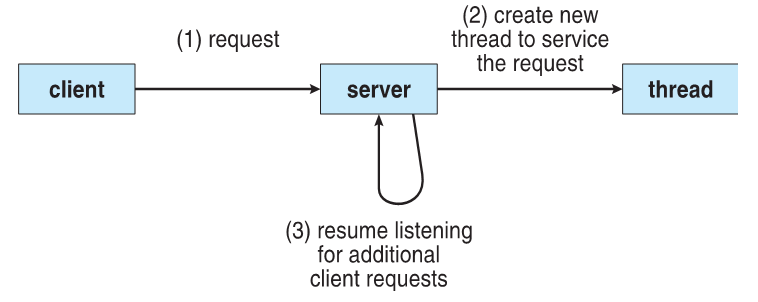
A classic example of a multi-threaded application is a web-server.
Why might a web-server need to employ threads to manage their tasks?
Many clients request the server's resources, but in serving a single client, the server cannot ignore other incoming requests.
Threads vs. Processes
Threads and Processes appear to be quite similar in that they both represent (at some level of abstraction) a delegation of labor to some other computational unit.
However, from what we can piece together from the above, there are some scenarios wherein we may prefer multiple processes compared to multiple threads, and vice versa.
Process Strengths:
Greater isolation between parent / child: no shared resources by default, and if child crashes, easy to kill, does not disrupt parent (e.g., Bash).
Address spaces can be repurposed: the
fork() -> exec()chain is a very common practice in the Unix philosophy, and provides dynamism for repurposing memory for another executable entirely.
Thread Strengths:
Similar tasks, same data sources: for example, many different operations to perform on a single source of data (like a massive data-set)
One process, much
wait: if a process must frequently wait for some I/O requests or other pauses, but other tasks could be running during that time, a multi-threaded approach may be useful.
With this conceptual backbone in place, let's look at some examples!
Linux Threads
Disclaimer: this is the "primitive" view of Linux threads; we'll look at what is used in practice (thread libraries) next time.
The POSIX primitive thread creation syntax is done via the clone system call, which is parameterized by flags that can customize what parts of the
parent process is shared by the thread:
CLONE_FSshares FS info / state like working directoryCLONE_VMshares the memory space (shared heap and data segment)CLONE_FILESshares open filesCLONE_SIGHANDsignal handlers shared (to be discussed)
How is this thread "customization" done in Linux?
Let's pull the wool back a little bit on the implementation of processes in Linux:
In Linux OS', there is no distinction between processes and threads, but rather, both are typically referred to as tasks.
In the Linux Kernel, task Process Control Blocks (PCBs) are stored as task_structs with pointers to components of the task's memory image.
When a subprocess is created (i.e., via
fork()) a newtask_structis created along with a copy of the parent's memory image.When a thread is created (i.e., via
clone()with the proper sharing tags) a newtask_structis created but the same memory image as the parent can be pointed to by the thread'stask_struct.
Draw the task_structs corresponding to a spawned subprocess vs. a new thread and their footprints in memory.
So, really, fork() is just clone() with no sharing parameters!
Next time, we'll see this in action, juxtaposed with a thread library's higher-level implementation!