Introduction
Welcome to CMSI 4320: your window into the cromulent world of cognitive systems!
Course Outline
For those of you viewing from home, at this point we'll review the class syllabus, located here:
Site Structure
Before we get started, some things to note about these course notes and the site you're currently viewing:
You can add notes inside the website so that you can follow along and type as I say stuff! Just hit SHIFT + N and then click on a paragraph to add an editable note area below. NOTE: the notes you add will not persist if you close your browser, so make sure you save it to PDF when you're done taking notes! (see below) Having said that, know that there is a lot of research that suggests taking hand-written notes to be far more effective at memory retention than typing them.
The site has been optimized for printing, which includes the notes that you add, above. I've added a print button to the bottom of the site, but really it just calls your printer functionality, which typically includes an option to export to PDF.
The course notes listed herein will have much of the lecture content, but not all of it; you are responsible for knowing the material you missed if you are absent from a lecture.
Any time you see a blue box with an information symbol (), this tidbit is a definition, factoid, or just something I want to draw your attention to; typically these will help you with the conceptual portions of the homework assignments.
Any time you see an orange box with a cog symbol (), this tidbit is a useful tool in your programming arsenal; typically these will help you with the concrete portions of your homework assignments.
Any time you see a red box with a warning symbol (), this tidbit is a warning for a common pitfall; typically these will help you with debugging or avoiding mistakes in your code.
Any time you see a teal box with a bullhorn symbol (), this tidbit provides some intuition or analogy that I think provides an easier interpretation of some of the more dense technical material.
Any time you see a yellow question box on the site, you can click on it...
...to reveal the answer! Well done!
With that said, let's jump right into it!
A Preview of Causal Inference
We begin our journey (per usual) with a little review:
Inference
In CMSI 3300 we saw propositional logic for logical inference, and Bayesian networks for probabilistic inference...
What does it mean to perform inference and how is it useful?
Inference is the ability to take evidence in some format (e.g., propositional logic knowledge bases or Conditional Probability Tables) and deduce facts from them that may not be explicitly stated.
Inference is useful in a number of contexts, including: for autonomous agents to make decisions, or for human policy-making (e.g., enacting laws or medical decisions).
Indeed, inference is something that humans perform with immediacy and ease, and has given us great intellectual dynamism.
Logical Inference allows agents to draw unstated conclusions from premises.
All humans are mortal.
Socrates is human.
What can we infer about Socrates?
Probabilistic inference took the above logical syllogisms and converted them to statements of chance.
This "fuzzy logic" gave us or our agents the ability to reason over what was most *likely*, e.g.,:
Is it more likely than not that seeing a house's lights on indicate that someone is home?
What is the likelihood that someone has lung cancer given symptoms of coughing and weakness (while taking into account the raw likelihood of cancer)?
Prediction tasks (like regression) can also be considered a form of probabilistic inference, since they provide the most likely / average output given some input to a learned function.
Suppose we are predicting home prices (\(Y\)) given their square footage (\(X\)) in some locale. The training data we may have already collected is depicted below, and we would like to, for any given \(X\) in the future, be able to predict its \(Y\).
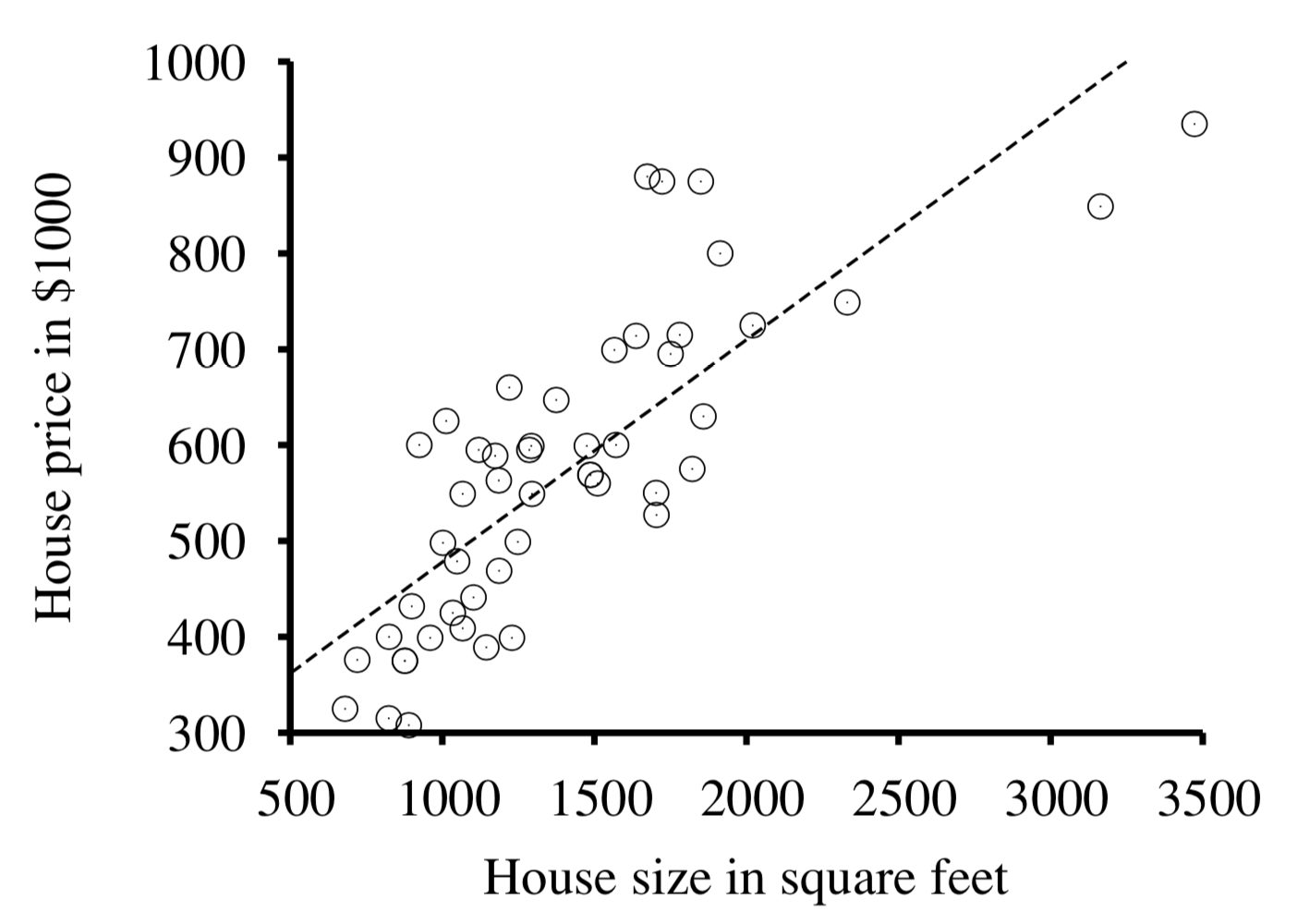
For many prediction tasks, regression alone is enough to answer queries of interest.
For example, to answer how much an about-to-be-listed 3000 sq. ft. house is likely to cost, we could:
Fit a regression line \(f\) to the existing data to learn some \(f(\text{House Size}) = \text{House Price}\)
Simply evaluate \(f(3000)\)
These simple, associational queries are well handled by traditional probability and statistics, but there are also interesting and valuable inferences that are not...
Motivating Examples
Here are some examples that the tools of CI can help us solve, or at least understand.
Example #1 - Murderous Ice Cream: suppose we are measuring Ice Cream Sales [I] and Murders [M] in the US, and find that they tend to covary (i.e., they tend to go up / down together). What are some causal stories / explanations for this setting?
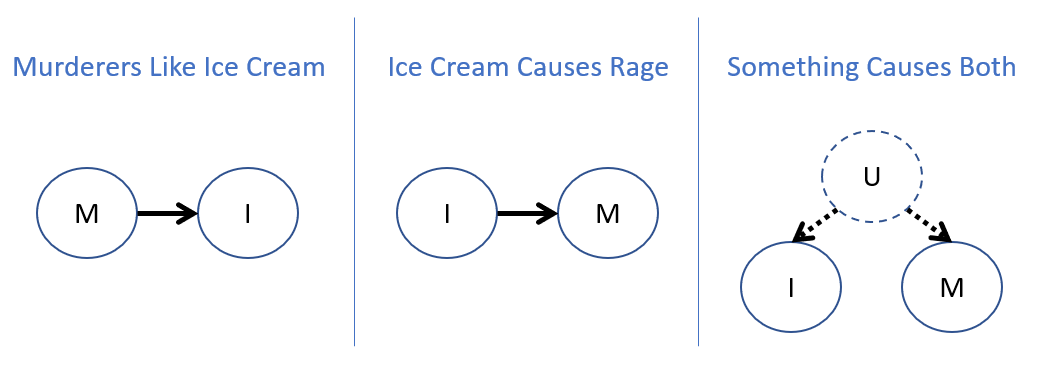
What would be a reasonable "common cause" in the 3rd model to explain the covariance between \(I, M\)?
The weather! During the heat of summer, people eat more ice cream and are more irritable.
Noitce that in all of the models above, \(I, M\) will be related, but the causal assumptions are different in each. E.g., in only one of these models, we would expect that performing some sort of intervention to increase ice-cream sales (e.g., by enacting a law to make it tax-free) would change the rates of murder. Which one would this apply to?
The middle model, because ice cream sales have a causal impact on murder.
This distinction between correlation and causation is important not only to the data sciences, but to artificial agents as well, who must distinguish evidence observed, and hypotheses about the effects of their own actions!
As another example, if you, like me, are a registered couch potato, graphs like the following might look encouraging.
Example #2 - Couch Potato's Dream: The following data was collected observationally, from medical records comparing cholesterol (Y-axis) and exercise (X-axis), as well as the age of each participant (i.e., each dot). Below, suppose we ignore the age associated with each person and fit a regression line to the aggregated data.
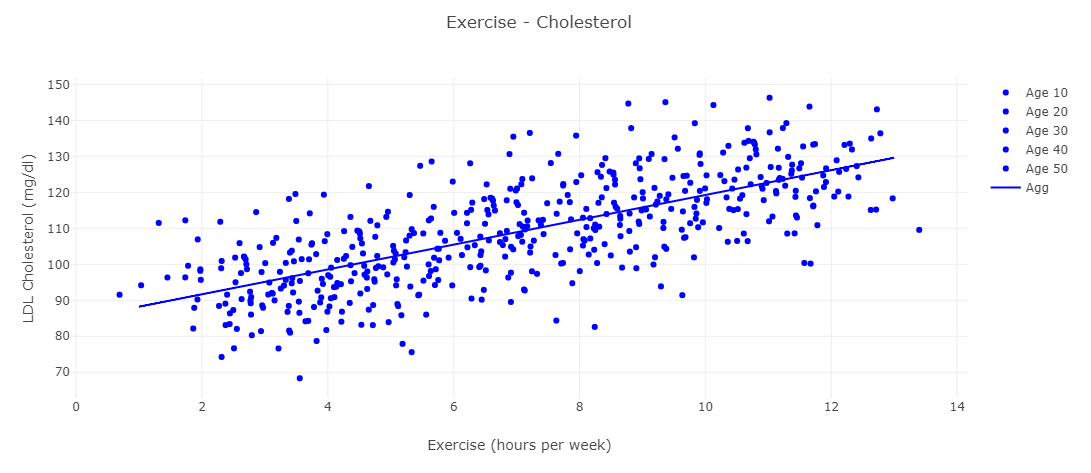
What does the graph above suggest about exercise and how would that inform your decision to work out?
It appears to suggest that more exercise is correlated with higher cholesterol! Everyone stop working out immediately!
Consider the same dataset but now wherein we fit regression lines to trends within the data segregated by age.
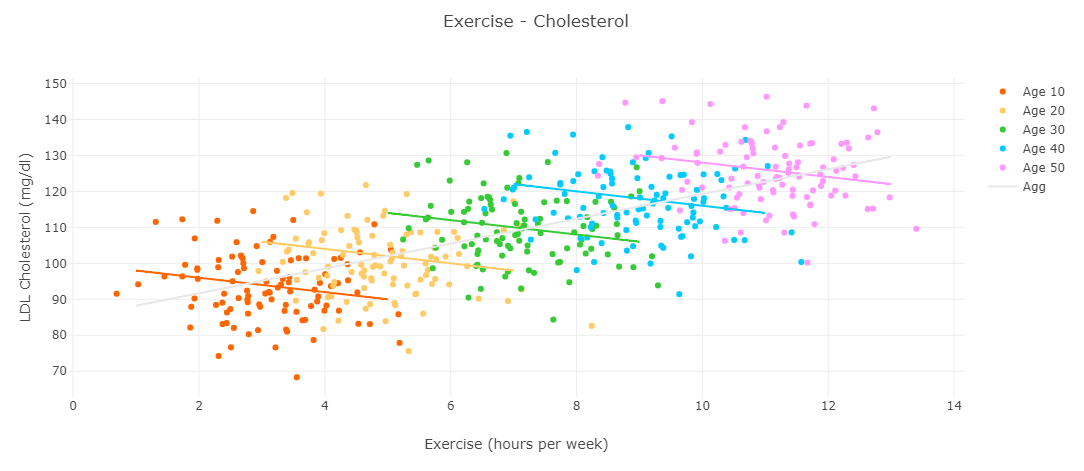
Firstly, what operation that we learned about from Bayesian probability theory does the above graph represent?
Conditioning! We condition the full dataset on age, and can then examine other variables of interest within each age-specific strata.
What does this NEW graph of each age-segregated dataset suggest about exercise and how would that inform your decision to work out?
It appears that, within *all* age groups, exercise lowers cholesterol! Everyone, quick! Head to the treadmills!
Now, crucially, reflect: which interpretation is right? Should we exercise or not, and why? (fingers crossed for the prior)
We may have some intuitive answers here, but we need some defendable formalisms to answer this question definitively.
It turns out that the above scenario represents a known issue for the statisticians of yore:
In probability and statistics, Simpson's Paradox occurs when a trend appears in some dataset, but then disappears (or is reversed) upon controlling for some other set of variables.
Simpson's Paradox plagued statisticians for many years, until the tools of causal inference provided some answers. These answers amount from a single, motivating impetus:
Motivating Impetus for Causal Inference: to answer some inference queries or to explain some data, many answers or explanations cannot come from the data alone, but rather, require assumptions about the system from our models of it.
This is also more akin to how we as humans think based on our own cognitive models, often requiring inferences beyond data alone!
This observation is not merely of interest to statisticians and data analysts, but to artificial agents as well, who must be able to make decisions from experience that might look an awful lot like the dataset depicted above.
What constitutes "context" that analysts and agents should attend to will be another important topic of this course.
So, to form the so called "Causal Models" that answer these questions, we need to take a step back and examine the Causal Inference Philosophy of Science, on which many of our modeling assumptions are built.
The Causal Inference Philosophy of Science
Generally speaking, philosophy of science is concerned with the scientific method's purpose, what it is able to measure, and how it models reality.
Whew, what a definition. "Did we sign up for a core class?" you might be asking.
Well, no, but it's important that, if we're trying to find a way to interpret data, we know what we're measuring and how we're going to structure our models!
The foundations of causal inference propose the following:
Causal Inference Philosophy of Science: there is a "DNA of the Universe" as modeled by a system of causes and effects such that:
The universe has some amount of determinism: We can predict the outcome of any effect with perfect accuracy, if we know the state of all relevant causes to a given effect.
Probability and statistics emerge because, due to the limitations of scientific measurement and knowledge, we *cannot* always know the state of all relevant causes.
However, modeling what causes and effects that we *can* will aid us in answering interesting inference queries, interpretting data, and crafting advanced and interpretable artificial agents.
Or, pictorially, the DNA of the Universe is a staggeringly complex system of causes and effects (variables connected by their causal influences) that we can attempt to model, even if we're missing some of the pieces (thus requiring that we involve probs and stats):
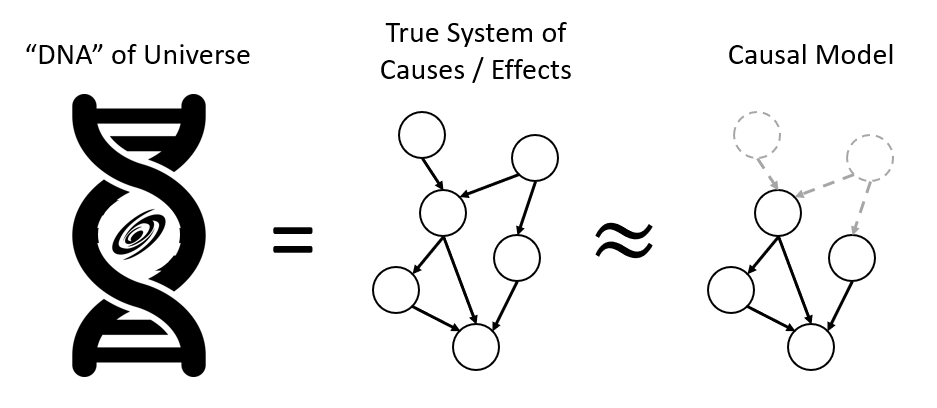
Don't look too closely at that double helix clip art and notice the sloppy edges around where I put yet another "universe" clip art, which is really a galaxy, but why split hairs? You got the idea.
Historical tidbit: this philosophy is aligned with Laplace's 1814 conception of natural phenomena in which "randomness surfaces owing merely to our ignorance of the underlying boundary conditions."
The capacity of our model to answer certain queries of interest depends upon the causal assumptions that we've encoded into it, and sometimes, our model confesses that it *cannot* answer a query of interest.
So, to summarize, what exactly do we mean by the field of "causal inference?"
Causal Inference is a framework for modeling reality as a system of causes and effects that provides a formal interpretation of data and enables powerful inference queries that can approximate human higher-cognitive functions.
The first half of this course will be devoted to "climbing" this ladder, learning the formalisms that comprise each of its wrungs.
A Preview of Reinforcement Learning
Now that we've taken a look at causal inference, let's pivot to the second part of the course... starting with a little context, again from CMSI 3300:
Review
In the design of artificial agents, we know that machine learning aids us, as programmers, in fashioning an AI that is too complex to encode from the top-down.
We discussed several categories of Machine Learning; what were they and what were their hallmarks?
Supervised Learning agents learn behaviors / predictors from large numbers of examples, i.e., paired features and labels / outcomes.
Unsupervised Learning agents attempt to cluster or otherwise expose relations in unlabeled data.
Reinforcement Learning agents learn actions in response to situations or contexts, as through the feedback of a "reward function," which determines the desirability of certain actions taken in certain states.
Note that there are not clean divisions between the various approaches to machine learning, and there will be some overlap in a variety of strategies we'll examine.
In CMSI 3300, we focused primarily on Supervised Learning, as in the era of "big data," the most widely applicable agents and analyses fall into this category.
In the latter half of CMSI 4320, we'll examine Reinforcement Learning in great depth, and see how it is an important supplement in your ML arsenal.
Reinforcement Learning (RL) in a Nutshell
To motivate RL, we consider a single, important fact in our own lives:
There is no book on how to be a human.

Nor are there books on how to be a Dog, or a Cat, or any other animal... yet here we all are today!
Why is there no book on How to Be a Human? Even if there was, why would it never sell?
Well, children can't read, so that'd be a big one, and obviously there are a lot of important things to learn in adolescence that can't wait until they can.
What works for one individual may not for another -- there can be no definitive guide because of the scientific principle of "Different Strokes."
It's possible that there are important questions to life to which no one actually knows the answer! How to be creative or discover if we're told to behave in a set fashion by someone who has tread perhaps a suboptimal path?
Obviously, parenting fills the important role for an absence of such a book, but we also have an "on-board compass" that gives us the basics through a very similar mechanic that RL attempts to do.
The human reward system includes a variety of neural structures that are responsible for associative learning and provide us with "rewards" (a feeling of satiety due to the release of the neurotransmitter dopamine) when we accomplish certain tasks.
What are some examples of said tasks? I'll let Wikipedia sum up the "primary" ones:

Indeed, there are certain behaviors that our own biology rewards, that no one formally need "teach" us, and these reward systems have persisted despite our exhibiting higher cognitive functions.
By analogy, just as there is no book on How to Be a Human, so too may there be machine learning tasks for which there is no labeled data, or for which we do not know how to label, or for which offline learning is out of the question... and so we instead rely on RL techniques to optimize our agent's behavior.
Take our Pacman Trainer from CMSI 3300 wherein we trained a deep-imitation learner to play Pacman on a small board. Why might RL be more appropriate for this task?
Some reasons include:
The overfitting was out of control -- our agent could barely perform on a simple map wherein the pellets stayed in the same place, let alone with the introduction of ghosts.
Massive amounts of data were required from humans, which could be impractical or costly for many complex tasks.
Even if we *did* train it successfully for a particular map from human data, that doesn't mean that the humans are the best at the game -- there might be better policies possible than the one we're emulating!
This brings us to a characterization of Reinforcement Learning, now that we have seen (and felt!) the analog in our own biology.
Reinforcement Learning is a class of both problems and algorithms in machine learning characterized by the following primary traits:
Reward, Trial, and Error: the learning agent is the actor in its environment learning, through repeated experimentation, to maximize some reward for actions taken.
Delayed Reward and Attribution: agents may need to choose lesser goods in the immediate to obtain greater goods in the future, and also learn what features in their environment are attributed to reward receipt.
So what are some instances of Reinforcement Learning in practice?
Examples
Example #1: Online Advertising Agents that must learn which ads to show to individuals of which demographics to maximize clickthroughs online.

"Hey, isn't that the same guy from the How to Be a Human book?" ... well yea, but what do I look like, a graphic artist?
Why is online, digital advertising better suited as a reinforcement learning problem rather than a supervised learning one?
Why bother paying for some labeled dataset of ad preferences when you can deploy and learn from your ad consumers directly?
Example #2: AlphaGO, a now famous RL agent that defeated the grandmaster of the game of Go.

Why are some game-playing agents better suited as a reinforcement learning problem rather than a supervised learning one?
A couple reasons, chiefly that: the state space of Go is massive, and a supervised learning dataset would need to be untenably large, and if we trained the agent only on games that humans have played, the agent would never surpass them!
Fun anecdote: previous human Go Grandmasters have studied the games played by AlphaGo and improved their own play in tournaments! Humans learning from AI!
Example #3: AlphaStar, one of the most impressive state-space tackling Starcraft II players from DeepMind that involves topics from pretty much every one of our past classes with me! [my start and end points added to the embed below; feel free to watch the whole thing for more context!]
Note the weaknesses of AlphaStar above!
Overfitting and generalization still haunt RL agents -- the amount of engineering and person-power required just to get it ready for the Starcraft ladder was enormous.
AlphaStar still does not *understand* what it's learning -- at some level, reinforcement learning is just supervised learning wherein the agent can generate its own samples.
Plainly, in this course, we won't be designing agents at the level of AlphaStar, but we'll look at the foundational principles that eventually led to its development, such that with the time, resources, and motivation, you too could do something similar for an application of interest.
Much fun to be had!
On Cognitive Systems
So why these two primary topics in pursuit of Cognitive Systems Design?
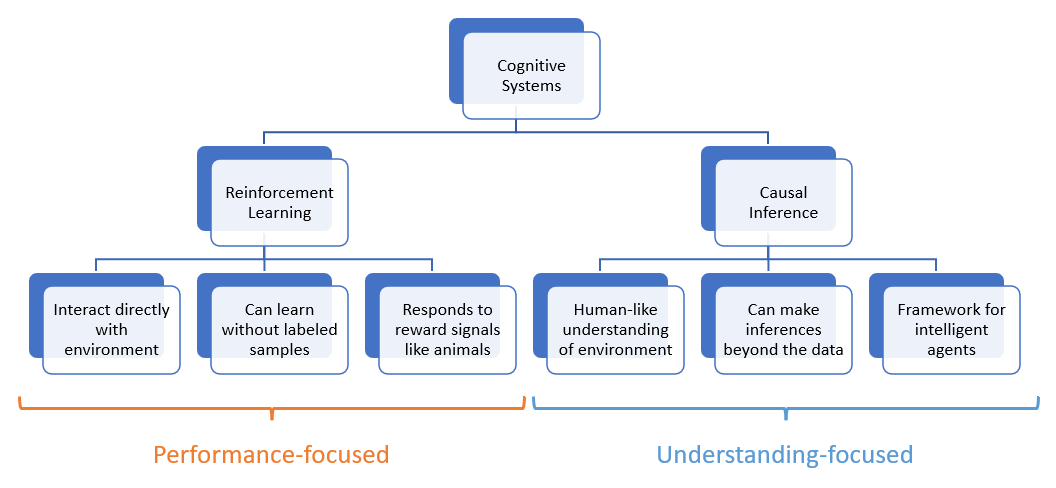
Causal Inference provides tools high on metrics of interpretability and inference, but is largely a theoretical framework with many fruits to be picked toward implementation into other disciplines in AI.
Causal inference also provides recipes for higher cognitive tasks like counterfactual reasoning that humans perform.
Reinforcement Learning provides tools high on metrics of performance and scale, but is difficult to interpret and easy to overtrain.
RL agents are lower-level animalistic agents that, while still impressive in their abilities, are guided by simple tendencies of reward that correlates some actions to "getting a cookie," others to "getting a slap on the wrist," and with much work to be done in transferring learning to other tasks apart from those in which training took place.
As such, there is much to be said for the model-based methods in RL that are emerging (especially as vehicles for interpretable AI), for which causal inference has much to say as well.
[!] Fair Warning: This is a class that will be heavily mathematical (as is much of modern AI) and begin largely in the domain of theory, but whose payoff will be grand if you stay the course!
[!] More disclaimer: This course is experimental! Although its topics are sometimes broached in graduate courses, this class will attempt to give them an approachable slant and fusion that has not been attempted before.
Finally, given the above, tell me: what are you expecting from this class? What are you interested in knowing a bit more about the topics of focus?
That said, I look forward to discussing not only the theory, mathematics, psychology, and philosophy behind the topics of this course. Here's to the next steps!