RL Features
Thus far, you might've come to the conclusion that feature-based RL is the clear winner for designing most agents, and in general, these approaches have seen impressive performance.
Here's a depiction of the Approximate, Feature-Based Q-Learning we've been using up until now:
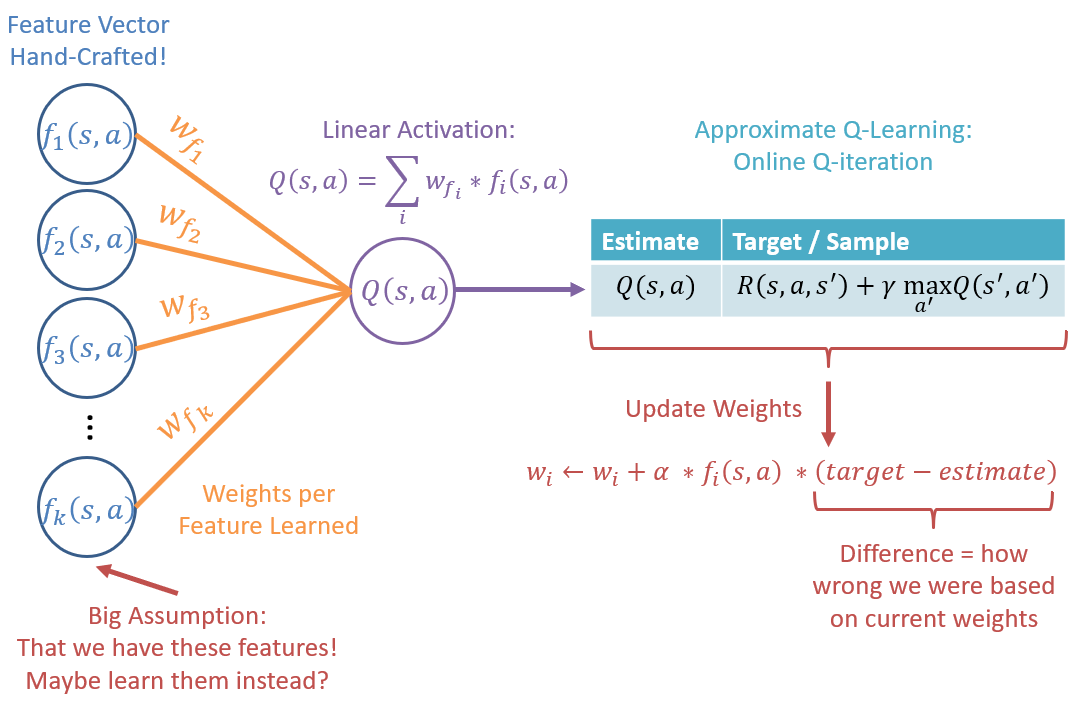
That said, there's a fairly large assumption that these feature-based agent's have had even beginning the learning process; what is that assumption?
That the features are already hand-picked, and the feature-extractor hand-crafted!
Plainly, this is too general an assumption, and for many domains, hand-picking and crafting the features can be a major drawback:
We may not even know where to begin with choices of features, especially if the state-action space is too complex.
Even if we could choose some good, representative set of features, encoding the feature-extractor can be impractical or time-consuming.
This may feel like a familiar dilemma from 485 -- wherein did it occur and what tools did we start to use to address it?
We saw this with some of our classification models, wherein it may be difficult to choose features and so instead rely on a neural network to, in some representation, learn them for us!
As such, for our next topic, we'll examine deep reinforcement learning, and how application of neural networks can apply to our tasks at hand!
Deep Q-Learning
Deep Q-Learning describes a class of approximate q-learners that, instead of a linear-q-value function, deploy some neural-network architecture to approximate q-values instead.
The benefits of using a NN for this task are that we no longer have to hand-pick features, but can instead rely on the network to focus on facets of the primitive state for us.
To understand a bit about how these techniques operate, we'll divert into a small review on their underlying tool.
Tiny Neural Network Review
Neural networks are, succinctly stated, general non-linear function approximators!
In brief: if you know what your inputs \(X\) are, and you know what constitutes "the right answer" \(Y_i\) to each input \(X_i\), you can deploy a neural network to learn the \(f\) in \(f(x) = y\)
Why does the property of being a non-linear function approximator sound appealing to us in the present task?
We can use it to estimate \(Q(s, a)\); it's a function after all!
Deep Q-Networks (DQNs) have many variant structures, but generally, possess an input layer that accepts the primitive state, some number of hidden layers to learn and weight features, and a final output estimating Q-values.
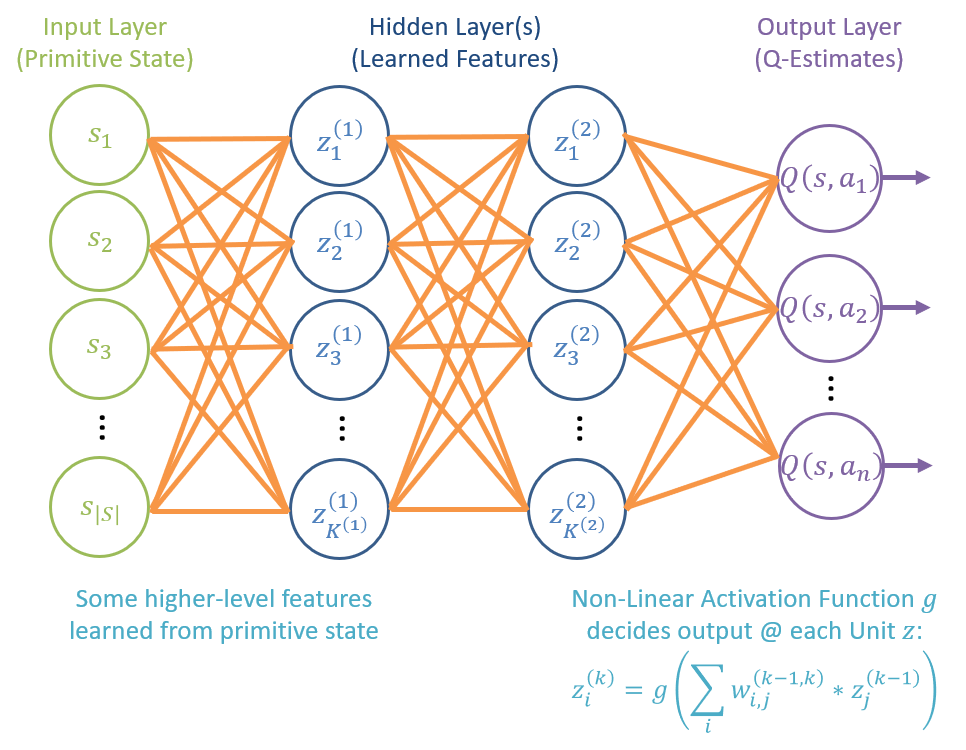
Notable parts of the above structure:
Inputs: encode the primitive state. These can be as rich as the Pacman gameboard (when even those higher-level representations are available) or as low-level as the pixels composing the screen of a game.
Hidden Layers: the "deep" in DQN, generally required to be many layers deep for more complex problem spaces; here's where the feature learning occurs (when it can), though is particularly opaque.
Outputs: estimates for each Q-value.
Weights: each edge in orange is accompanied by a weight, similar to those attached to features in our approximate q-learning.
Activations: each unit \(Z_i\) has an output that is some differentiable, non-linear function of the weighted sum of its inputs.
The general form of learning in a neural network is still in finding the weights that best approximate the function trying to be learned, as mechanized by the backpropagation algorithm, through which differences / errors in the network's output vs. the expected target are used to tweak the weights to close the gap:
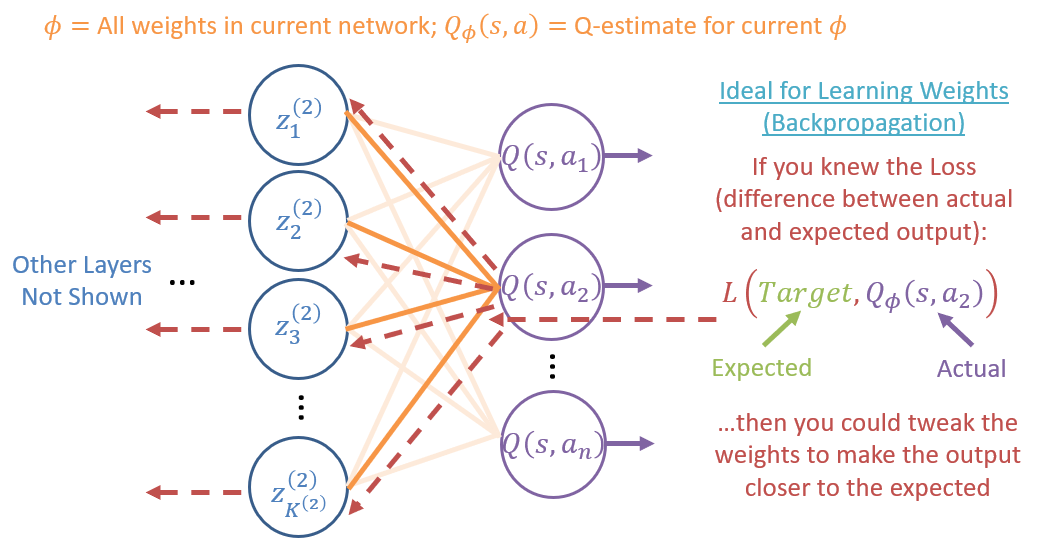
However, if we were attempt to naively deploy back-propagation in our online-Q-iteration algorithm, we run into some issues with DQNs:

Big takeaway: Q-learning (though it looks like it) is not the same as gradient-descent! Definition of a clear "target" is not well defined, because in the task of online exploration, our estimate of Q-values is always changing with new experiences!
Learning in a DQN
So, to address these issues, we turn to some clever tricks:
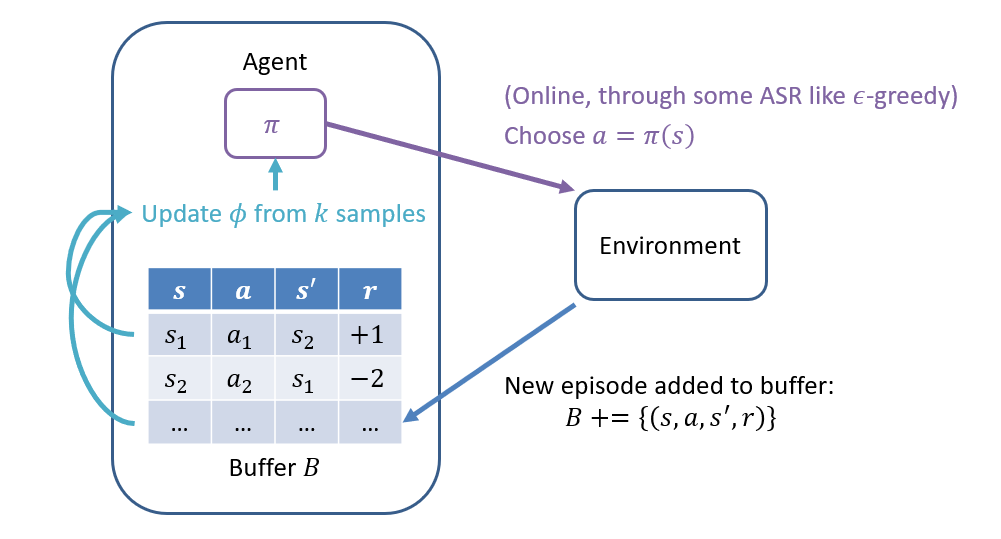
Decorrelating Samples: in order to prevent an issue known as "catastrophic forgetting" whereby lessons learned along a particular trajectory (correlated episodes) can be lost by learning later trajectories, we can deploy a replay buffer, a storage location for *all* episodes that can be sampled at random.
Effectively, this means that you can stash all of your agent's experiences in a memory bank, and then periodically reflect on them to learn!
Fixing a Target: in order to enable a gradient with a fixed target, we can introduce a second DQN known as the target network with a separate set of weights \(\phi'\) such that the target network provides a stationary bullseye, and is then periodically updated as the OG network learns.
Depicted, we see an iterative process by which the OG network is updated while sampling, and then essentially "leapfrogs" its weights with the target network.
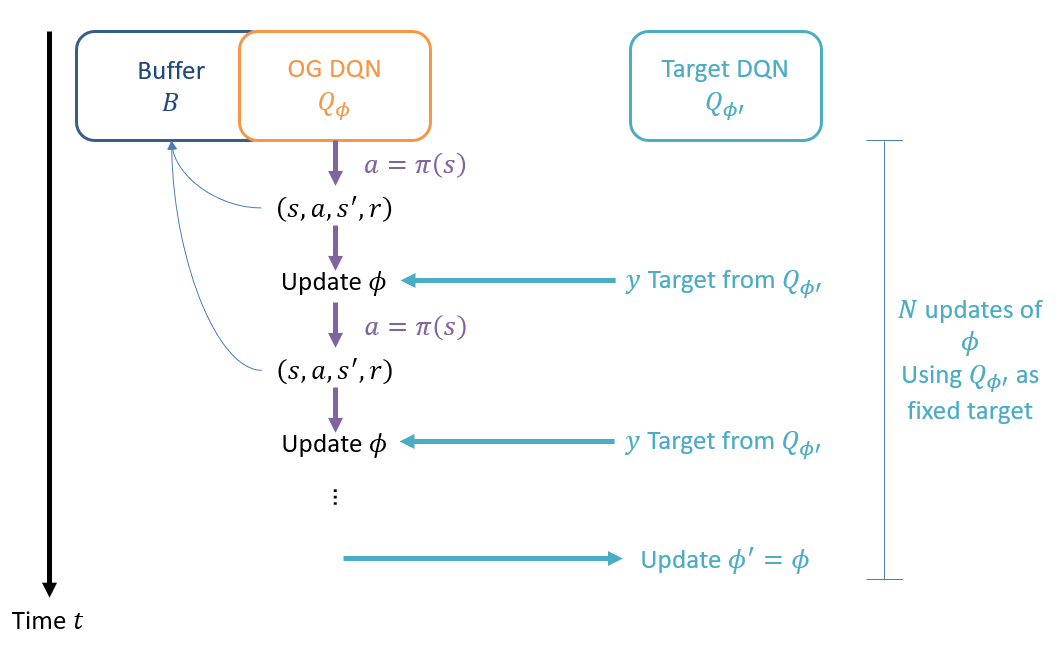
Putting it all together leads us to the following algorithm (Summary credit to Dr. Sergey Levine):

Powerful stuff!
The drawbacks of deep-q-learning (in a nutshell):
Neural Networks overfit (that's their job!), so transportability is an issue with Q-values estimated in this way.
Interpretability of "learned" features from the network is low, so it's difficult to determine just what higher-order features the network finds important from the lower-level state.
In practice, in order for weights to converge during training, DQNs require a well-oiled machine, from having good sampling, reward function, and a variety of the other concerns we've discussed in the past lectures.
There are entire classes devoted to Deep-Q-Learning that warrant a graduate-level coverage, but you should look into some of these tools on your own!
Still, there are others who believe that Deep-Q-Learning may be another passing phase in which different tools are needed to overcome their transportability issues, so while these might be some of the most modern approaches, just note that they are not the ultimate form of RL -- no one knows that yet!
Further Reading
There are so many tricks just to get a DQN to converge on a workable policy; you should look at some of these other promising tricks and tools:
Double Q-Learning
Actor-Critic Methods for Q-Learning
Q-learning with Convolutional Networks
So what are some of the other cool areas of study in RL at the present?
Modern Research
Given that Deep-Q-Learning has seen a lot of popularity, there are still *many, many* avenues to explore. Here are a selection of some fun ones with decent amounts of promise.
Inverse Reinforcement Learning
Now that we've seen some powerful ways of learning state-feature representations through deep Q-learning, we should address another piece of the RL puzzle that might be hard to define.
What might be another facet of RL that could be difficult for a programmer to define, and that we might try to learn instead?
The reward function!
This is no easy task, and is often ill advised, since the reward function specifies precisely what we want our agent to do!
Still, we should hint at some scenarios whereby we might want to learn the reward function rather than provide it:
Watching an expert play a video game and then inferring just *what* rewards they're trying to get?
Learning how to walk by watching someone else walk.
If you want to go down a trippy rabbit hole: look up "Mirror Neurons" in the brain and how they're believed to help infants learn.
Critically, we see a bit of a trend in the sparse examples above:
Inverse Reinforcement Learning is the process of inferring a reward function from expert demonstrations.
"Givens" |
Traditional RL |
Inverse RL |
|---|---|---|
Environment |
States and actions |
States and actions |
Model |
Transitions and Rewards (in fully-specified) |
Transitions (in fully-specified) and some set of expert actions \(\{(s_1, a_1), (s_2, a_2), ...\}\) sampled from \(\pi^*(s)\) |
Goal |
Learn \(\pi^*(s)\) |
Learn \(R(s, a, s') \Rightarrow \) Learn parameters of some linear reward function or neural net... then use that to learn \(\pi^{*}(s)\) |
In words: the objective is to learn the reward the expert is trying to maximize.
A fascinating exploration that is a *really* hard problem and hasn't seen a lot of traction, but for which causal inference might have some things to say WRT probability of necessity and sufficiency of certain features to be observed in states in which the expert acts!
Transfer Learning
The number one challenge with anything involving neural networks: transportability -- being able to take training in one environment and use that same network / agent in a separate environment with key differences.
This is something humans do quite easily, as we've mentioned numerous times in this course, but to motivate it, here's a small example (once more, a game -- can you tell why I like RL?)
Take the old Atari game that has traditionally been used in many Transfer Learning domains: Montezuma's Revenge:

Some notables in the (already rich, but hilariously low-rez) frame shown:
Even if you've never played Montezuma's Revenge, you probably see the key and understand that it's used to open something -- a useful first objective to acquire.
If you made the insight above, you've likely just experienced transfered learning, since knowledge about keys in the past (both in real life and many other games) has transferred into this one without you needing to take a single step.
Transfer Learning is the ability to take learned behavior in one environment and translate it to reduce the need for exploration in another.
Generally, this is a very difficult and open problem, but there are several key avenues in current pursuit:
Forward Transfer: train in 1 environment, transfer that training to another
Multi-task Transfer: train on several environments with commonalities, transfer to another
Meta-Learning: learn to learn from several environments with commonalities
Meta-learning, in particular, has seen much traction in recent years, but there is still much to be done here!
If you look up Causal Transportability, there's a lot to say here -- perhaps the future is in concerting the two!
Reinforcement Learning - Concluding Remarks
What a wild first half of the semester it has been! Thus far we've:
Examined some ways to model the sequential decision tasks that, perhaps, you and I respond to on a daily basis.
Seen some neat algorithms for both online and offline MAB + MDB solving, and appreciated some of their strains, weaknesses, and strengths.
Taken a good, hard, look in the mirror and asking what rewards we respond to as humans just trying to navigate the day O_O
Fun Videos
Here are some great links you should check out when you have the time! We'll review a few in class together.
The Next State
That said, as powerful as these tools are, we're just starting to scratch the surface of what makes intelligent beings... well... intelligent!
If we as humans *only* responded to reward signals, we would not be nearly the successful species that we are... there's something more behind our cognitive capacities that goes beyond our animalistic tendencies.
So, join me in Part 2, as we begin to think about thinking, and then think some more about how to encode our thinking for the next generation of intelligent agents!